Deep Recurrent Q-Network (DRQN)¶
论文链接: https://cdn.aaai.org/ocs/11673/11673-51288-1-PB.pdf
深度循环 Q 网络(Deep Recurrent Q-Network,DRQN)是 DQN 的一种扩展,旨在处理部分可观测环境。 DQN 通常依赖完全可观测的 马尔可夫决策过程(Markov Decision Process,MDP), 而 DRQN 引入循环神经网络(Recurrent Neural Network,RNN), 用于处理部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process,POMDP)。 在此类环境中,智能体无法直接获得环境的完整状态。
下表列出了 DRQN 算法的一些基本特征:
DRQN 的特征 |
是否具备 |
说明 |
|---|---|---|
同策略(On-policy) |
❌ |
评估策略与目标策略相同。 |
异策略(Off-policy) |
✅ |
评估策略与目标策略不同。 |
无模型(Model-free) |
✅ |
无须预先构建环境动力学模型。 |
基于模型(Model-based) |
❌ |
需要使用环境模型训练策略。 |
离散动作 |
✅ |
可处理离散动作空间。 |
连续动作 |
❌ |
可处理连续动作空间。 |
网络结构¶
DRQN 使用 RNN 替换 DQN 中的全连接层,通常采用 LSTM 或 GRU。
门控循环单元(GRU) |
长短期记忆网络(LSTM) |
|---|---|
|
|
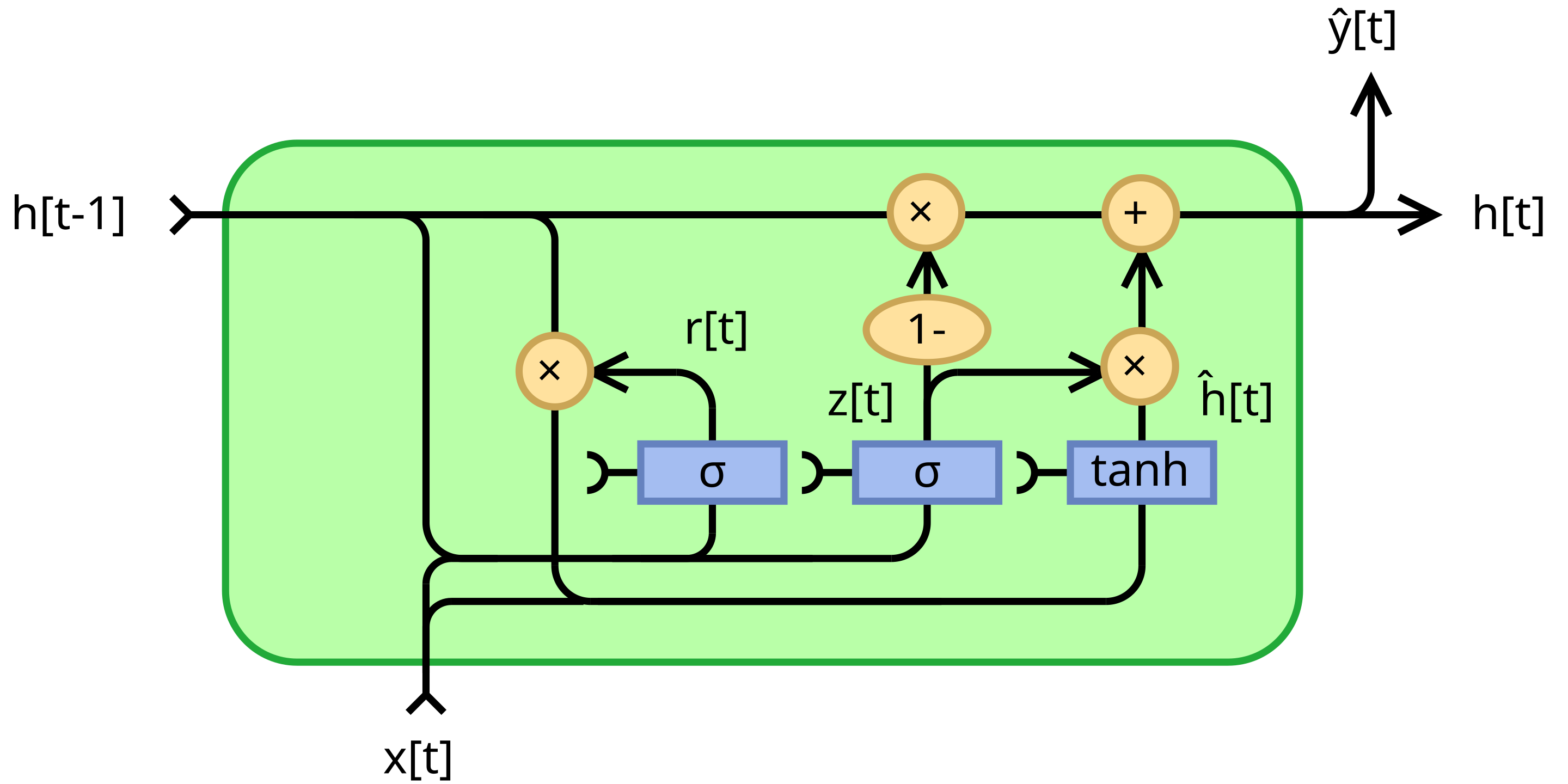
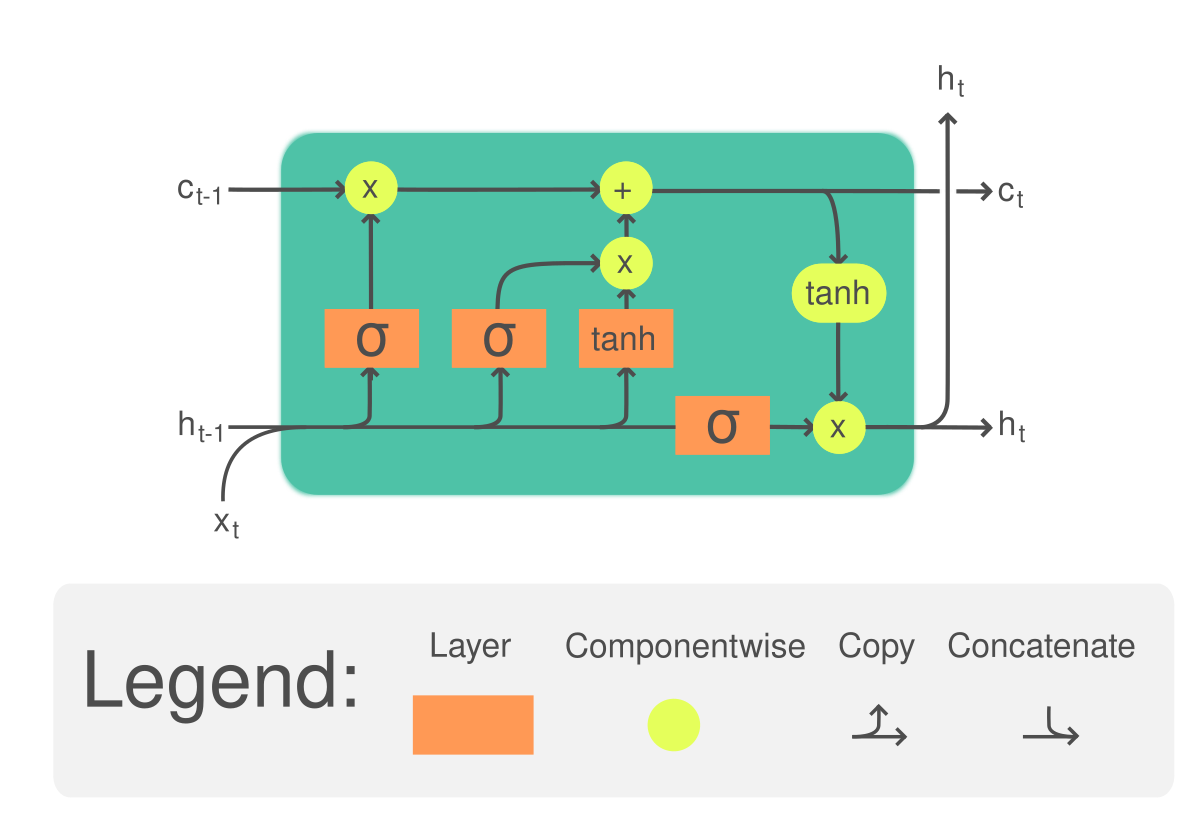
这种结构使网络能够保留过去观测的信息,从而推断环境中不可直接观测的隐状态。
DRQN 不再仅依赖当前时刻的观测, 而是使用一段观测序列,即历史信息,预测 Q 值。 RNN 对观测序列进行处理,并与标准 DQN 一样,为每个动作输出相应的 Q 值。
DQN 与 DRQN 的主要区别如下:
特征 |
DQN |
DRQN |
|---|---|---|
网络类型 |
前馈 CNN 或全连接层 |
循环网络(LSTM/GRU) |
观测输入 |
单个观测 |
观测序列 |
适用场景 |
完全可观测的 MDP |
部分可观测的 POMDP |
记忆机制 |
无记忆机制 |
能够捕获时间依赖关系 |
在 XuanCe 中运行 DRQN¶
在 XuanCe 中运行 DRQN 之前,需要先准备一个 conda 环境,并按照
安装步骤安装 xuance。
运行内置示例¶
完成安装后,可以打开 Python 控制台,并使用以下命令直接运行 DRQN:
import xuance
runner = xuance.get_runner(method='drqn',
env='classic_control', # 可选项:claasi_control、box2d、atari。
env_id='CartPole-v1', # 可选项:CartPole-v1、LunarLander-v2、ALE/Breakout-v5 等。
is_test=False)
runner.run() # 也可以使用 runner.benchmark()
使用自定义配置运行¶
如需使用不同配置运行 DRQN,可以新建一个 .yaml 文件,例如 my_config.yaml。
然后使用以下代码运行 DRQN:
import xuance as xp
runner = xp.get_runner(method='drqn',
env='classic_control', # 可选项:claasi_control、box2d、atari。
env_id='CartPole-v1', # 可选项:CartPole-v1、LunarLander-v2、ALE/Breakout-v5 等。
config_path="my_config.yaml", # 请确保 my_config.yaml 文件的路径正确。
is_test=False)
runner.run() # 也可以使用 runner.benchmark()
如需进一步了解配置方法,请参阅 配置教程。
在自定义环境中运行¶
如需在 XuanCe 尚未包含的自定义环境中运行 DRQN,
需要按照新环境教程
中的步骤定义新环境。
然后,准备配置文件
drqn_myenv.yaml。
完成上述操作后,可以使用以下代码在自定义环境中运行 DRQN:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import DRQN_Agent
configs_dict = get_configs(file_dir="drqn_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = DRQN_Agent(config=configs, envs=envs) # 创建一个来自 XuanCe 的 DRQN 智能体。
Agent.train(configs.running_steps // configs.parallels) # 对模型进行多个步骤的训练。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 结束训练。
参考文献¶
@inproceedings{hausknecht2015deep,
title={Deep recurrent q-learning for partially observable mdps},
author={Hausknecht, Matthew and Stone, Peter},
booktitle={2015 aaai fall symposium series},
year={2015}
}