Dueling Deep Q-Network (Dueling DQN)¶
论文链接: https://proceedings.mlr.press/v48/wangf16.pdf。
竞争深度 Q 网络(Dueling DQN)是对标准 DQN 网络架构的一种改进, 旨在提高 Q 值估计的效率与稳定性。 该方法引入了一种新的神经网络架构,分别估计状态价值函数 和动作优势函数,从而解决传统 DQN 中的一些关键局限。
下表列出了 Dueling DQN 算法的一些基本特征:
Dueling DQN 的特征 |
是否具备 |
描述 |
|---|---|---|
同策略(On-policy) |
❌ |
行为策略与目标策略相同。 |
异策略(Off-policy) |
✅ |
行为策略与目标策略不同。 |
无模型(Model-free) |
✅ |
无须预先构建环境动力学模型。 |
基于模型(Model-based) |
❌ |
需要使用环境模型训练策略。 |
离散动作 |
✅ |
可处理离散动作空间。 |
连续动作 |
❌ |
可处理连续动作空间。 |
Dueling DQN 的核心思想¶
令 \(V(s)\) 表示状态 \(s\) 的整体价值。 \(A(s, a)\) 是优势函数,用于衡量在状态 \(s\) 下采取特定动作 \(a\) 所带来的相对收益。 \(V(s)\)、\(A(s, a)\) 与 \(Q(s, a)\) 之间的关系为:
因此,状态–动作对的 Q 值可以表示为:
这种分解方式有助于将状态本身的价值与各个动作的优势解耦。 Dueling DQN 的网络架构如下图所示:
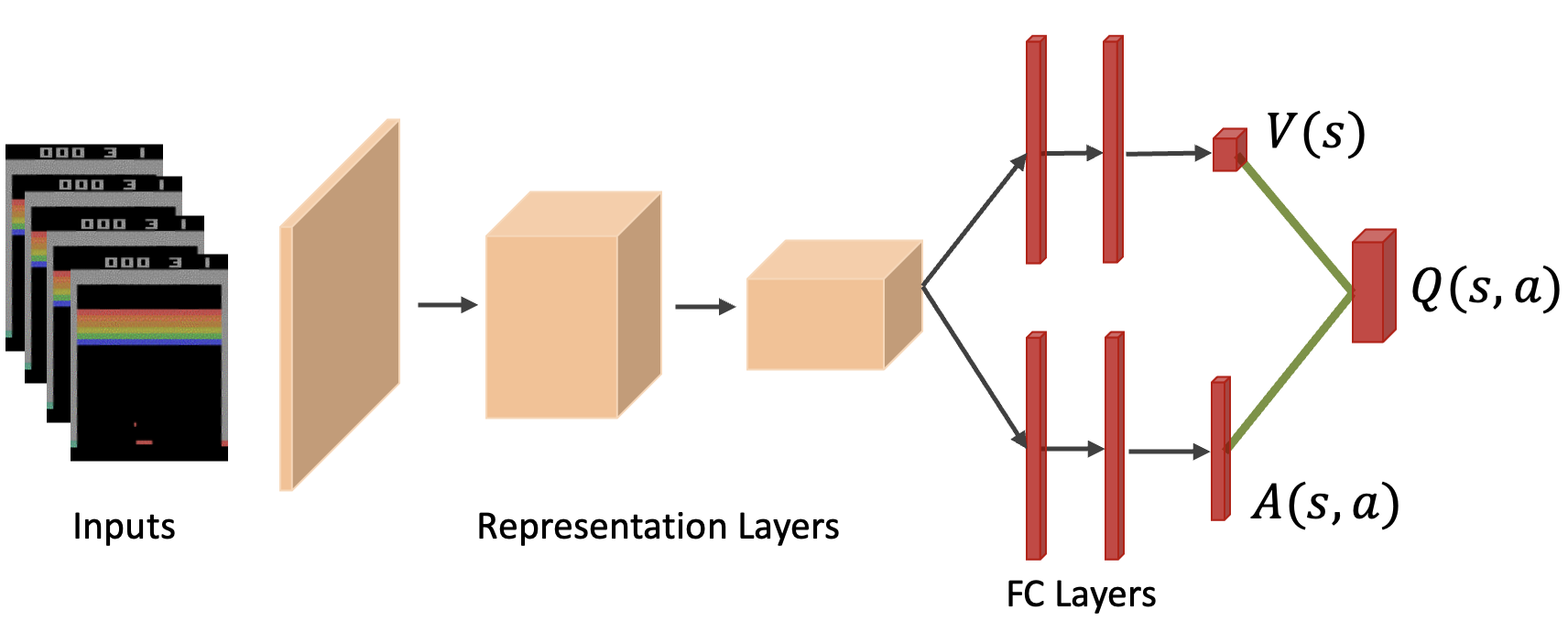
算法框架¶
XuanCe 中实现的 Dueling DQN,其智能体与环境之间的整体交互过程如下图所示。
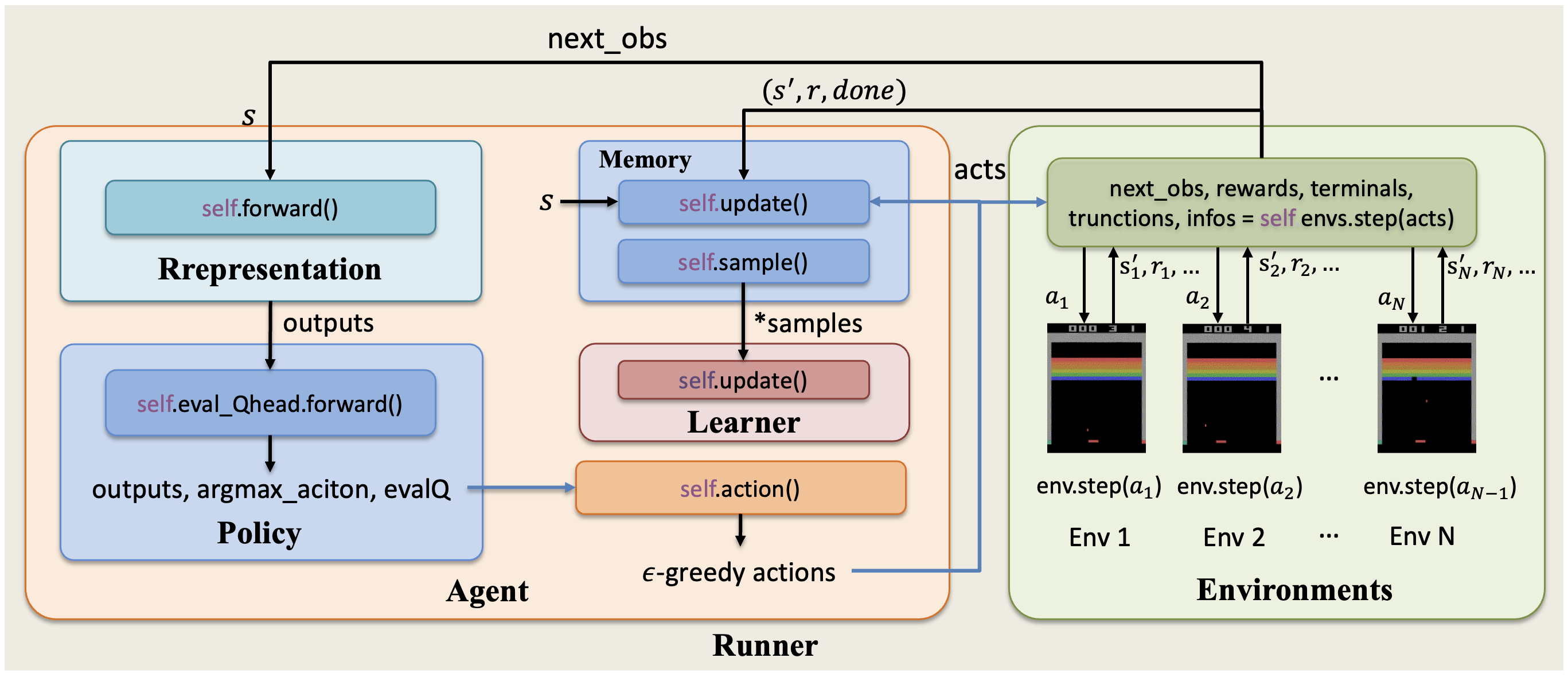
在 XuanCe 中运行 Dueling DQN¶
在 XuanCe 中运行 Dueling DQN 之前,需要准备一个 conda 环境,并按照
安装步骤安装 xuance。
运行内置示例¶
完成安装后,可以打开 Python 控制台,并使用以下命令直接运行 Dueling DQN:
import xuance
runner = xuance.get_runner(algo='dueldqn',
env='classic_control', # 可选项:classic_control、box2d、atari。
env_id='CartPole-v1', # 可选项:CartPole-v1、LunarLander-v3、ALE/Breakout-v5 等。
)
runner.run() # 也可以使用 runner.benchmark()
使用自定义配置运行¶
若要使用不同的配置运行 Dueling DQN,可以新建一个 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码运行 Dueling DQN:
import xuance
runner = xuance.get_runner(algo='dueldqn',
env='classic_control', # 可选项:classic_control、box2d、atari。
env_id='CartPole-v1', # 可选项:CartPole-v1、LunarLander-v3、ALE/Breakout-v5 等。
config_path="my_config.yaml", # 请确保 my_config.yaml 的文件路径正确。
)
runner.run() # 也可以使用 runner.benchmark()
若要进一步了解配置方法,请参阅 配置教程。
在自定义环境中运行¶
若要在 XuanCe 尚未内置的自定义环境中运行 Dueling DQN,
需要按照
新环境教程
中的步骤定义新环境。
随后,准备配置文件
duelqn_myenv.yaml。
完成上述步骤后,可以通过以下代码在自定义环境中运行 Dueling DQN:
import argparse
from xuance.common import load_yaml
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import DuelDQN_Agent
configs_dict = load_yaml(file_dir="duel_dqn_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = DuelDQN_Agent(config=configs, envs=envs) # 创建 XuanCe 的 Dueling DQN 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型指定数量的步数。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 结束训练并释放相关资源。
参考文献¶
@InProceedings{pmlr-v48-wangf16,
title = {Dueling Network Architectures for Deep Reinforcement Learning},
author = {Wang, Ziyu and Schaul, Tom and Hessel, Matteo and Hasselt, Hado and Lanctot, Marc and Freitas, Nando},
booktitle = {Proceedings of The 33rd International Conference on Machine Learning},
pages = {1995--2003},
year = {2016},
editor = {Balcan, Maria Florina and Weinberger, Kilian Q.},
volume = {48},
series = {Proceedings of Machine Learning Research},
address = {New York, New York, USA},
month = {20--22 Jun},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v48/wangf16.pdf},
url = {https://proceedings.mlr.press/v48/wangf16.html},
abstract = {In recent years there have been many successes of using deep representations in reinforcement learning. Still, many of these applications use conventional architectures, such as convolutional networks, LSTMs, or auto-encoders. In this paper, we present a new neural network architecture for model-free reinforcement learning. Our dueling network represents two separate estimators: one for the state value function and one for the state-dependent action advantage function. The main benefit of this factoring is to generalize learning across actions without imposing any change to the underlying reinforcement learning algorithm. Our results show that this architecture leads to better policy evaluation in the presence of many similar-valued actions. Moreover, the dueling architecture enables our RL agent to outperform the state-of-the-art on the Atari 2600 domain.}
}