独立 Q 学习 (IQL)¶
论文链接: https://hal.science/file/index/docid/720669/filename/Matignon2012independent.pdf.
1. 引言¶
完全协作多智能体系统(MAS)中的独立学习者(IL)是不通过通信学习的智能体,仅通过与环境的交互进行学习。核心代表是去中心化 Q 学习(IQL 的基本实现)。其目标是使智能体通过独立维护局部动作-价值函数收敛到全局帕累托最优纳什均衡。本文基于 Matignon 等人(2012)的经典论文,简要解释了 IQL 的算法、特性和实验验证。
2. IQL 算法特性表¶
IQL 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
✅ |
智能体之间没有通信;它们完全独立地学习和决策。 |
完全中心化 |
❌ |
没有用于统一决策的中央控制器。 |
中心化训练与去中心化执行(CTDE) |
❌ |
在训练和执行阶段都没有中央控制器;整个过程完全去中心化。 |
同策略 |
❌ |
评估策略与目标策略不同(基于 Q 学习的 IQL 通常是异策略的)。 |
异策略 |
✅ |
评估策略与目标策略不同,可以利用经验回放等异策略技术。 |
无模型 |
✅ |
不需要环境动力学模型;通过直接与环境交互进行学习。 |
基于模型 |
❌ |
不需要环境模型来辅助策略训练。 |
离散动作 |
✅ |
适用于离散动作空间。 |
连续动作 |
❌ |
不原生支持连续动作空间,需要通过离散化等方法进行扩展。 |
3. 独立学习者的核心协调问题¶
3.1 帕累托选择问题¶
存在至少两个不相容的帕累托最优均衡(\(\exists i, \pi_i \neq \hat{\pi}_i\) 且 \(U_{i,<\hat{\pi}_i, \pi_{-i}>}(s) < U_{i,\pi}(s)\)),智能体倾向于选择非最优的联合动作。
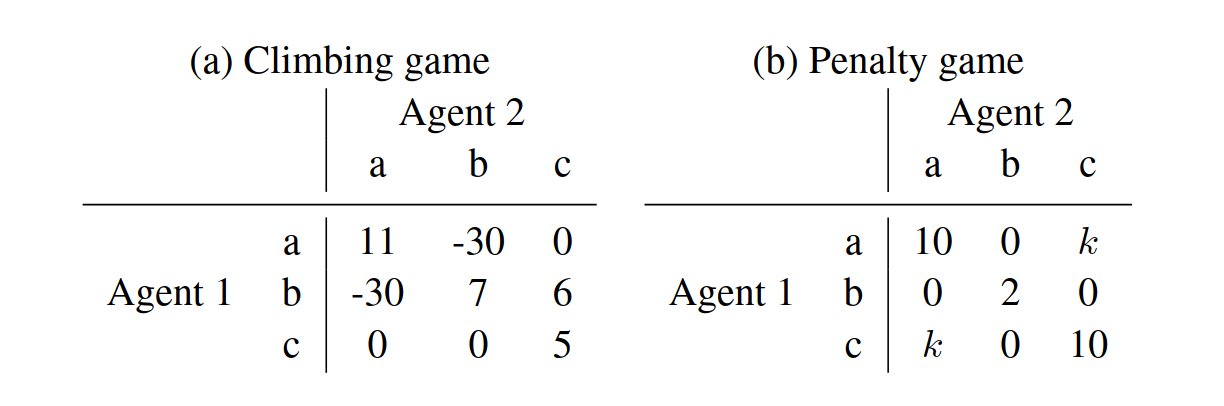
Figure 1 : 显示 Climbing/Penalty 收益,有助于理解帕累托均衡。¶
3.2 非平稳性问题¶
其他智能体的策略动态变化,导致从单个智能体的角度来看,转移概率 \(T(s,a_i,s')\) 是非平稳的,违反了单智能体强化学习的平稳性假设。
3.3 随机性问题¶
环境噪声(如随机奖励)使智能体难以区分”奖励波动是来自环境还是其他智能体的策略”。

Figure 2 : 显示随机 Climbing 收益,有助于理解环境随机性。¶
3.4 交替探索问题¶
单个智能体的探索动作会干扰其他智能体的学习。全局探索率为 \(\psi=1-(1-\epsilon)^n\)(\(n\) 是智能体数量,\(\epsilon\) 是个体探索率),这很容易触发策略破坏的恶性循环。
3.5 阴影均衡问题¶
均衡 \(\bar{\pi}\) 被策略 \(\hat{\pi}\) “覆盖”。存在一个智能体 \(i\),其从 \(\bar{\pi}\) 单方面偏离的收益低于从 \(\hat{\pi}\) 偏离的最小收益,导致选择次优的 \(\hat{\pi}\)(例如,在 Climbing 游戏中,\(<a,a>\) 被 \(<c,c>\) 覆盖)。
4. 核心算法:去中心化 Q 学习¶
4.1 Q 值更新公式¶
智能体 \(i\) 采取动作 \(a_i\) 后,根据奖励 \(r=R(s,<a_i,a_{-i}>)\) 和下一个状态 \(s'\) 更新 \(Q_i\):
其中 \(\alpha \in [0,1]\) 是学习率,\(\gamma\) 是折扣因子。
4.2 探索策略¶
ε-贪婪:以概率 \(\epsilon\) 随机选择动作,以概率 \(1-\epsilon\) 选择当前 \(Q_i\) 值最大的动作;
Softmax:基于玻尔兹曼分布选择动作,温度 \(\tau\) 控制探索程度:
论文推荐GLIE 策略(探索率随着学习迭代次数的增加而衰减到 0),确保在极限情况下具有贪婪行为。
5. 相关改进算法介绍¶
算法名称 |
核心改进 |
解决的核心问题 |
|---|---|---|
分布式 Q 学习 |
乐观更新(仅将 Q 值更新到历史最大值)+ 均衡选择(通过社会约定固定策略) |
阴影均衡、交替探索 |
滞后 Q 学习 |
双学习率(\(\alpha>\beta\):Q 增加时使用 \(\alpha\),Q 减少时使用 \(\beta\)) |
随机性、阴影均衡 |
递归 FMQ |
基于”动作的最大奖励频率”对 Q 值进行插值,以平衡乐观性和准确性 |
随机性、交替探索(仅适用于矩阵博弈) |
WoLF PHC |
双策略学习率(\(\delta_L>\delta_W\):失败时快速学习,获胜时慢速学习) |
非平稳性、交替探索 |
6. 实验验证与可视化¶
6.1 矩阵博弈实验¶
为了验证算法在单状态博弈中的收敛性,结果如下表所示:
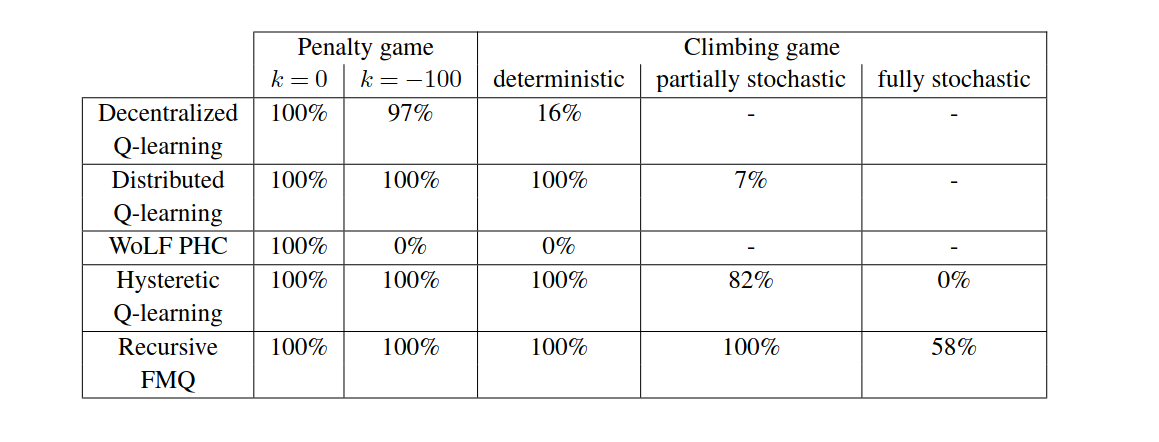
Table 1 : 比较 IQL 算法在博弈中的收敛率,显示协调性能。¶
6.2 GLIE 参数敏感性实验¶
去中心化 Q 学习严重依赖 GLIE 策略参数(如 Softmax 的 \(\tau_{ini}\) 和 \(\delta\)),结果如下表和图所示:

Table 2 : 显示去中心化 Q 学习在 GLIE 下的收敛性,反映参数影响。¶
6.3 多智能体扩展实验¶
当智能体数量增加时算法鲁棒性的变化如下表所示:
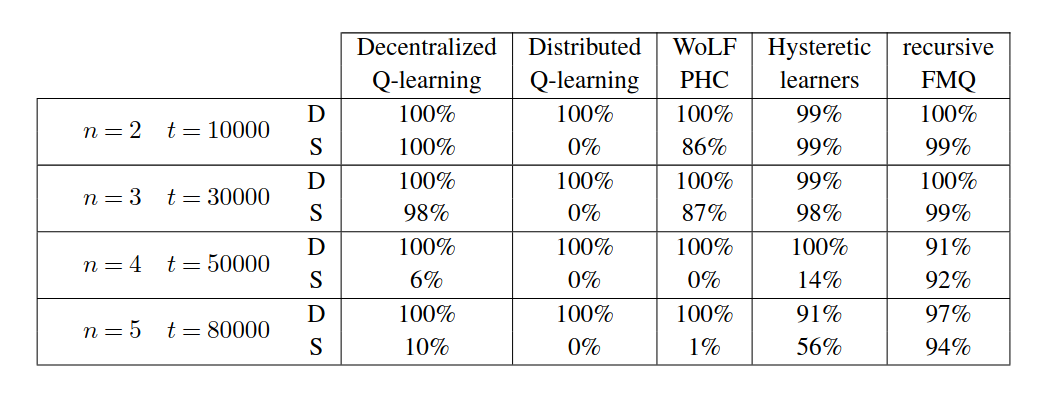
Table 3 : 显示算法在不同智能体数量下的收敛性,表明 IQL 的鲁棒性。¶
7. 算法优缺点分析¶
7.1 去中心化 Q 学习(基本 IQL)的优点¶
实现简单:不需要通信,只需要维护局部 Q 值;
开销低:存储和计算随智能体数量线性增长;
通用性强:适用于各种完全协作场景(如多机器人任务)。
7.2 去中心化 Q 学习的缺点¶
对 GLIE 参数的依赖:难以调优,直接影响收敛性;
对阴影均衡的敏感性:在 Climbing 游戏中收敛率极低;
对随机性的抵抗能力差:环境噪声容易导致 Q 值估计偏差。
8. 相关算法伪代码介绍¶
本文提供了 IQL 及其改进的 3 个核心伪代码,作为直接实现参考。
8.1 分布式 Q 学习伪代码¶
实现 IQL 的乐观更新:初始化(随机策略,\(Q_{i,\text{max}}\) = 最小奖励),ε-贪婪动作选择,乐观 \(Q_{i,\text{max}}\) 更新,均衡选择。适用于确定性协作马尔可夫博弈。

解决 IQL 的阴影均衡/交替探索;在确定性博弈中 100% 收敛(论文验证)。
8.2 WoLF PHC 伪代码¶
针对 IQL 的非平稳性:初始化,基于策略的动作选择,TD Q 值更新,双速率调优(\(\delta_W\) 用于获胜,\(\delta_L\) 用于失败)。

增强对其他智能体策略的适应性;减少非平稳性/交替探索带来的波动。
8.3 递归 FMQ 伪代码¶
针对 IQL 在单状态矩阵博弈中的随机性:初始化,\(Q_i\)/\(F_i\) 更新,通过 \(F_i\) 进行线性插值,均衡选择。仅适用于矩阵博弈。

区分环境随机性和探索;在部分随机矩阵博弈中 100% 收敛。
在 XuanCe 中运行 IQL¶
在 XuanCe 中运行 IQL 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 IQL:
import xuance
# 为 IQL 算法创建运行器
runner = xuance.get_runner(method='iql',
env='sc2', # 选择:sc2, mpe, robotic_warehouse, football, magent2.
env_id='3m', # 选择:3m, 2m_vs_1z, 8m, 1c3s5z, 2s3z, 25m, 5m_vs_6m, 8m_vs_9m, MMM2 等。
is_test=False) # False 用于训练,True 用于测试
runner.run() # 开始运行(或 runner.benchmark() 用于基准测试)
使用自定义配置运行¶
如果您想使用不同的配置运行 IQL,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 IQL:
import xuance as xp
# 为 IQL 算法创建运行器
runner = xp.get_runner(method='iql',
env='sc2', # 选择:sc2, mpe, robotic_warehouse, football, magent2.
env_id='3m', # 选择:3m, 2m_vs_1z, 8m, 1c3s5z, 2s3z, 25m, 5m_vs_6m, 8m_vs_9m, MMM2 等。
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False) # False 用于训练,True 用于测试
runner.run() # 开始运行(或 runner.benchmark() 用于基准测试)
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 IQL,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
iql_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 IQL:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_MULTI_AGENT_ENV
from xuance.environment import make_envs
from xuance.torch.agents.multi_agent_rl.iql_agents import IQL_Agents
configs_dict = get_configs(file_dir="iql_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_MULTI_AGENT_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = IQL_Agents(config=configs, envs=envs) # 从 XuanCe 创建 IQL 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@article{matignon2012independent,
title={Independent Reinforcement Learners in Cooperative Markov Games: A Survey Regarding Coordination Problems},
author={Matignon, Laetitia and Laurent, Guillaume J and Le Fort-Piat, Nadine},
journal={The Knowledge Engineering Review},
volume={27},
number={1},
pages={1--31},
year={2012},
publisher={Cambridge University Press},
doi={10.1017/S0269888912000057},
url={https://hal.science/file/index/docid/720669/filename/Matignon2012independent.pdf}
}