Q-混合网络 (QMIX)¶
论文链接: ICML 2018. 论文链接: JMLR 2020.
在之前对 VDN 算法的介绍中,我们提到了 QMIX。
尽管 QMIX 是 VDN 的改进版本,但它们不是由同一团队发表的。 它由牛津大学的 Whiteson 研究实验室和俄罗斯-亚美尼亚大学(共同第一作者)联合开发, 发表在 ICML 2018(2018 年国际机器学习会议), 是多智能体强化学习领域的知名算法。
下表列出了 QMIX 算法的一些一般特性:
QMIX 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
❌ |
评估策略与目标策略相同。 |
异策略 |
✅ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
❌ |
处理连续动作空间。 |
研究背景与动机¶
对于 MARL 问题,我们之前多次提到”中心化训练与去中心化执行(CTDE)”。 本文还假设多个智能体在执行动作时只能观测各自的局部状态信息, 而在训练阶段,它们可以访问所有智能体的观测、动作以及系统的全局状态。 对于协作任务,在 CTDE 下需要解决的关键问题是如何找到最优的去中心化策略,使得 团队的”状态-联合动作”价值函数 \(Q_{tot}\) 得到优化。
为此,VDN 算法提出将 \(Q_{tot}\) 分解为 \(Q_i\)(其中 \(i = 1, \cdots ,n\))。 这里,\(Q_i\) 作为每个智能体计算最优动作的 Q 值函数, 并且使用分解形式 \(Q_{tot} = \textstyle\sum_{i=1}^n Q_i\) 对网络进行端到端训练。 然而,这种基于简单求和的总价值函数分解大大限制了网络的功能逼近能力, 使得难以拟合真实的 \(Q_{tot}\)。
如果我们直接使用标准神经网络来分解 \(Q_{tot}\)——例如,\(Q_{tot} = MLP(Q_1, \cdots ,Q_n)\)—— 我们可以提高网络的功能逼近能力, 但会遇到另一个问题:非单调性,这使得算法难以保证去中心化策略的最优性。 ——我们可以提高网络的功能逼近能力,但会遇到另一个问题:非单调性, 这使得算法难以保证去中心化策略的最优性。
单调性意味着由去中心化策略计算的动作和 由总 Q 函数计算的动作在”性能最优性”方面必须一致,即:
这里,\(\tau\) 表示观测-动作序列的历史,\(u\) 表示动作。 如果公式\(`(1)`\)不成立,去中心化策略无法最大化 \(Q_{tot}\), 因此不会是最优的——这就是非单调性。
此时,您会注意到 VDN 的分解方法满足公式\(`(1)`\)中的单调性, 其中:
然而,这个公式中的关系过于受限。 实际上,价值函数分解的单调性只需要满足以下条件:
只要公式\(`(3)`\)成立,公式\(`(1)`\)中的单调性就得到保证。 这里,公式\(`(3)`\)是公式\(`(1)`\)的充分但不必要条件。
因此,本文的研究目标是设计一个神经网络,以 \(`\{Q_i\}_{i=1}^N`\) 作为输入并输出 \(`Q_{tot}`\),同时强制执行公式\(`(3)`\)中的单调性约束。 在这个约束下进行探索,我们不仅可以确保公式\(`(1)`\)成立, 还可以增强网络的功能拟合能力, 从而解决 VDN 算法的局限性。
算法设计¶
算法框架与设计原理¶
在 QMIX 算法中,\(Q_{tot}\) 由 \(n\) 个智能体网络、 一个混合网络和一组超网络表示。 通过直接查看图表更容易理解:
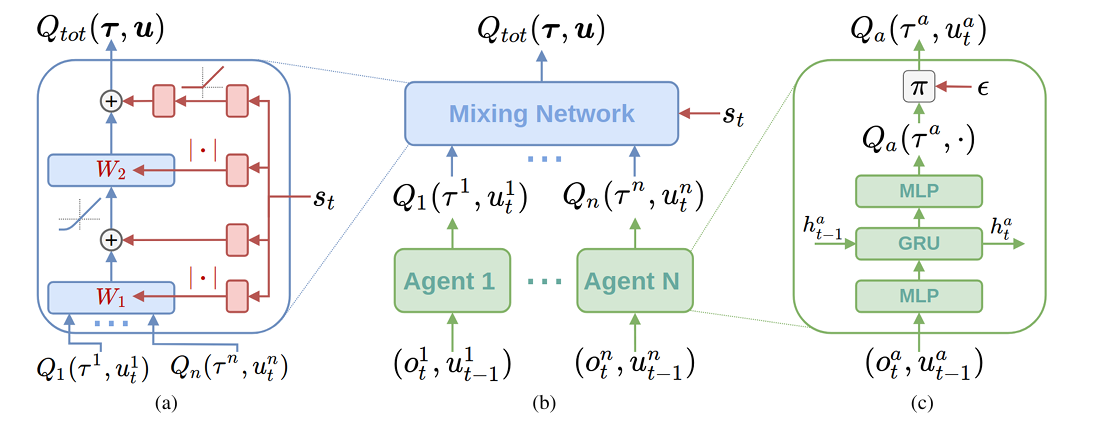
Figure 1: (a) 混合网络结构。红色是产生蓝色混合网络层权重和偏置的超网络¶
智能体网络由 \(MLP + GRU + MLP\) 组成。 它们的输入是各自智能体的观测-动作序列历史, 它们的输出是该智能体的分解 Q 值函数。 智能体使用此 Q 值推导出用于探索的 \(\epsilon -greedy\) 策略。
混合网络接受两个输入:所有智能体网络的输出 \(`\{Q_i(\tau^i,u_t^i)\}_{i=1}^N`\) 和系统的全局状态 \(`s_t`\)。它的输出是 \(`Q_{tot}(\boldsymbol{\tau},\boldsymbol{u})`\)。 值得注意的是,QMIX 使用 \(s_t\) 作为超网络的输入,然后超网络为混合网络生成参数。 这与 VDN 不同,VDN 不使用全局状态 \(s_t\)。
图 1 的关键部分是左侧混合网络的内部结构。 混合网络包括一个输入层、一个隐藏层和一个输出层。 与标准的单隐藏层 MLP 不同,其隐藏层的权重和偏置由另一组网络(超网络)计算。 混合网络隐藏层的激活函数是 ELU(指数线性单元), 输出层使用线性激活(无激活函数)。 从红色框图可以看出:
\(W_1\) 和 \(W_2\) 由两个单层线性网络后跟绝对值激活生成。
对应于 \(W_1\) 的偏置项直接由单层线性网络计算(无激活)。
对应于 \(W_2\) 的偏置项由两层线性网络计算,第一层使用 ReLU 激活。
超网络输出一个向量,然后重塑为混合网络的参数。
您可能会想知道为什么作者设计这样一种不寻常的结构来计算混合网络的参数。 实际上,这种设计确保混合网络的权重参数是非负的, 允许混合网络以任意精度近似任何单调函数(即满足公式\(`(3)`\))。
为了帮助读者更好地理解这个逻辑,我们展开混合网络的表达式:
这里,\(Q=[Q_{1}(\tau^{1},u_{t}^{1}),\cdots,Q_{n}(\tau^{n},u_{t}^{n})]\) 是一个 \(n\) 维向量, \(B_1\)、\(B_2\) 分别是对应于 \(W_1\)、\(W_2\) 的偏置项。 使用链式法则和线性变换的微分规则:
从 ELU 激活函数曲线及其一阶导数曲线, 我们知道 \(0<\frac{\partial\mathrm{Elu}(x)}{\partial x}\leq1\), 由于 \(W_1\)、\(W_2\) 中的每个元素都是非负的,\(\frac{\partial Q_{\mathrm{tot}}}{\partial \boldsymbol{Q}}\) 中的每个元素(即 \(\frac{\partial Q_{\mathrm{tot}}}{\partial Q_i}\))也是非负的, 所以公式 \(`(3)`\) 成立。
从以上分析,我们只需要确保权重矩阵 \(W_1\) 和 \(W_2\) 中的元素是非负的就可以实现我们的目标 ——不需要对偏置项 \(B_1\) 或 \(B_2\) 进行任何限制。
然而,有人可能会问:以这种方式构建的网络能否作为通用函数逼近器?
作者参考以下论文的结论来回答这个问题: 原始论文链接。
该论文表明,当神经网络的权重参数被限制为非负时, 它理论上可以以任意精度 \(\epsilon\) 近似以下单调函数:
参数训练¶
由于所有超网络的输入是全局状态 \(s_t\) 且超网络的输出是混合网络的参数, 需要训练的参数包括超网络参数和智能体网络参数。
作者使用端到端训练来最小化以下损失函数:
其中 \(b\) 是批次大小, \(y^{tot}=r+\gamma\max_{\boldsymbol{u}^{\prime}}Q_{tot}(\boldsymbol{\tau}^{\prime},\boldsymbol{u}^{\prime},s^{\prime};\theta^{-})\), \(\theta^{-}\) 表示目标网络参数。具体的训练过程类似于 DQN。
因为混合网络的设计确保公式\(`(1)`\)成立,求解 \(\max_{\boldsymbol{u}^{\prime}}Q_{tot}(\boldsymbol{\tau}^{\prime},\boldsymbol{u}^{\prime},s^{\prime};\theta^{-})\) 可以通过分别最大化每个智能体的价值函数来实现。这大大简化了求解 max 函数的计算复杂度。
函数表示复杂度¶
尽管 QMIX 比 VDN 具有更强的函数拟合能力, 作者还指出公式\(`(3)`\)中的约束仍然限制了它可以拟合的价值函数范围。 这是因为一些价值函数分解可能不是基于满足这个单调性约束——公式\(`(3)`\)是公式\(`(1)`\)的充分但不必要条件。
对于某些去中心化策略,其中单个智能体的最优动作同时依赖于其他智能体的动作, QMIX 算法的函数表示能力也会受到一定程度的限制。 然而,无论如何,QMIX 仍然比 VDN 更强大。
结论¶
QMIX 算法在理论和实验验证方面都比 VDN 具有更多优势。 作为基于价值的 MARL 算法,它受到研究人员的广泛青睐。
然而,正如作者所指出的,QMIX 在执行策略时不考虑其他智能体的动作。 这在实际情况中有些不合理。对于涉及协作任务的多智能体场景, 只有充分考虑其他智能体对自己决策的潜在影响,才能实现更好的协作。 因此,考虑智能体之间更复杂的关系——例如任务/角色分配 和智能体通信——也是 QMIX 算法扩展的重要方向。
此外,公式\(`(3)`\)是公式\(`(1)`\)的充分但不必要条件, 这在一定程度上限制了 QMIX 网络的函数逼近能力。 在某些场景中,这导致拟合的 \(Q_{tot}\) 与真实值 \(Q_{{tot}}^*\) 之间存在差距。
在 XuanCe 中运行 QMIX¶
在 XuanCe 中运行 QMIX 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 QMIX:
import xuance
runner = xuance.get_runner(method='qmix',
env='mpe', # 选择:football, mpe, sc2
env_id='simple_spread_v3', # 选择:simple_spread_v3 等
is_test=False)
runner.run()
使用自定义配置运行¶
如果您想使用不同的配置运行 QMIX,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 QMIX:
import xuance as xp
runner = xp.get_runner(method='qmix',
env='mpe', # 选择:football, mpe, sc2
env_id='simple_spread_v3', # 选择:simple_spread_v3 等
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run() # 或 runner.benchmark()
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 QMIX,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
qmix_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 QMIX:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import QMIX_Agents
configs_dict = get_configs(file_dir="qmix_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = QMIX_Agents(config=configs, envs=envs) # 从 XuanCe 创建 QMIX 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@InProceedings{pmlr-v80-rashid18a,
title={QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning},
author={Rashid, Tabish and Samvelyan, Mikayel and Schroeder, Christian and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon},
booktitle={Proceedings of the 35th International Conference on Machine Learning},
pages={4295--4304},
year={2018},
editor={Dy, Jennifer and Krause, Andreas},
volume={80},
series={Proceedings of Machine Learning Research},
month={10--15 Jul},
publisher={PMLR}
}
@article{rashid2020monotonic,
title={Monotonic value function factorisation for deep multi-agent reinforcement learning},
author={Rashid, Tabish and Samvelyan, Mikayel and De Witt, Christian Schroeder and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon},
journal={Journal of Machine Learning Research},
volume={21},
number={178},
pages={1--51},
year={2020}
}