反事实多智能体策略梯度算法 (COMA)¶
论文链接: https://ojs.aaai.org/index.php/AAAI/article/view/11794.
反事实多智能体策略梯度(COMA)是一种用于多智能体协作问题的强化学习算法。它旨在通过减少策略梯度的方差来提高去中心化智能体的学习性能。
该算法由 DeepMind 团队首次提出。论文标题为 “Counterfactual Multi - Agent Policy Gradients”,由 Jakob Foerster 等人于 2017 年在 AAAI 会议上发表。它适用于具有局部观测和去中心化决策的多智能体环境,特别是策略梯度方法下的协作问题。
下表列出了 COMA 算法的一些一般特性:
COMA 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
✅ |
评估策略与目标策略相同。 |
异策略 |
❌ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
❌ |
处理连续动作空间。 |
动机¶
部分可观测和去中心化决策¶
在协作多智能体系统中,为单智能体设计的强化学习方法通常在复杂的强化学习任务中表现不佳,因为智能体的联合动作空间随着智能体数量呈指数级增长。通常需要重新采用去中心化策略,其中每个智能体仅基于其局部动作-观测历史选择自己的动作。此外,执行过程中的部分可观测性和通信约束可能需要在联合动作空间不是特别大的情况下也使用去中心化策略。
信用分配¶
在协作环境中,联合动作通常只产生全局奖励,这使得每个智能体很难推断出自己对团队成功的贡献。有时可以为每个智能体设计单独的奖励函数。然而,这些奖励在协作环境中通常不可用,并且往往无法鼓励单个智能体为更大的利益做出牺牲。这通常严重阻碍了多智能体学习在具有挑战性的任务中,即使智能体数量相对较少。
核心思想¶
COMA 考虑一个完全协作的多智能体任务,可以描述为一个随机博弈 \(G\),由元组 \(G = \langle S, U, P, r, Z, O, n, \gamma \rangle\) 定义,其中 \(n\) 个由 \(a \in A \equiv \{1, \dots, n\}\) 标识的智能体选择顺序动作。环境具有真实状态 \(s \in S\)。在每个时间步,每个智能体同时选择一个动作 \(u^a \in U\),形成联合动作 \(\mathbf{u} \in \mathbf{U} \equiv U^n\),根据状态转移函数 \(P(s'|s, \mathbf{u}) : S \times \mathbf{U} \times S \to [0, 1]\) 在环境中引起转移。所有智能体共享相同的奖励函数 \(r(s, \mathbf{u}) : S \times \mathbf{U} \to \mathbb{R}\),\(\gamma \in [0, 1)\) 是折扣因子。
COMA 考虑部分可观测设置,其中智能体根据观测函数 \(O(s, a) : S \times A \to Z\) 获取观测 \(z \in Z\)。每个智能体有一个动作-观测历史 \(\tau^a \in T \equiv (Z \times U)^*\),基于此条件化随机策略 \(\pi^a(u^a|\tau^a) : T \times U \to [0, 1]\)。它用粗体表示智能体的联合量,用上标 \(-a\) 表示除给定智能体 \(a\) 外的智能体的联合量。
折扣回报是 \(R_t = \sum_{l=0}^\infty \gamma^l r_{t+l}\)。智能体的联合策略导出一个价值函数,即对 \(R_t\) 的期望,\(V^\pi(s_t) = \mathbb{E}_{s_{t+1:\infty}, \mathbf{u}_{t:\infty}} [R_t | s_t]\),以及动作价值函数 \(Q^\pi(s_t, \mathbf{u}_t) = \mathbb{E}_{s_{t+1:\infty}, \mathbf{u}_{t+1:\infty}} [R_t | s_t, \mathbf{u}_t]\)。优势函数由 \(A^\pi(s_t, \mathbf{u}_t) = Q^\pi(s_t, \mathbf{u}_t) - V^\pi(s_t)\) 给出。
COMA 的核心思想如下:
中心化训练,分布式执行¶
这是现代多智能体强化学习的主流范式。 训练阶段(学习):允许智能体访问全局信息(如地图和所有单位的位置),甚至在所有智能体之间共享经验。 执行阶段(执行):每个智能体只能基于其局部能观测到的内容做出决策。
COMA 利用这一点:每个智能体都有自己的”执行器”负责采取动作(去中心化执行)。然而,有一个统一的”评判器”,具有全知视角来评估整个团队的性能。
使用此中心化评判器的简单方法是让每个执行器根据此评判器估计的 TD 误差更新梯度:
反事实基线¶
在单智能体强化学习领域,优势函数常用于衡量特定动作相对于平均水平的优势程度。 其数学表达式为: $\( A(s, a) = Q(s, a) - V(s) \)\( 其中 \)Q(s, a)\( 表示在状态 \)s\( 下采取动作 \)a\( 的回报,\)V(s)\( 表示在状态 \)s$ 下随机采取动作的平均回报。也就是说,优势函数是采取某个动作的回报与随机采取动作的平均回报之间的差值。
然而,在多智能体环境中,由于其他智能体的动态行为导致环境剧烈变化和高噪声,”平均水平”的定义变得模糊。为了解决这一挑战,COMA 算法引入了反事实基线的概念。这一概念不再关注传统意义上的平均水平,而是强调反事实条件下的情况:即如果一个智能体改变自己的动作,而其他智能体的动作保持不变,结果是否会恶化。
COMA 的一个关键见解是,可以使用中心化评判器来实现差异奖励,从而避免这些问题。COMA 学习一个中心化评判器 \(Q(s, u)\),它估计基于中心状态 \(s\) 的联合动作 \(\mathbf{u}\) 的 Q 值。对于每个智能体 \(a\),我们可以计算一个优势函数,将当前动作 \(u_a\) 的 Q 值与边缘化 \(\mathbf{u}_a\) 的反事实基线进行比较,同时保持其他智能体的动作 \(\mathbf{u}^{-a}\) 固定:
\(A^a(s, \mathbf{u}^a)\) 为每个智能体计算单独的基线,使用中心化评判器来推理反事实,其中只有 \(a\) 的动作发生变化,直接从智能体的经验中学习,而不依赖于额外的模拟、奖励模型或用户设计的默认动作。因此,每个智能体可以获得更公平、更准确的反馈。
框架¶
下图显示了 COMA 的算法结构。
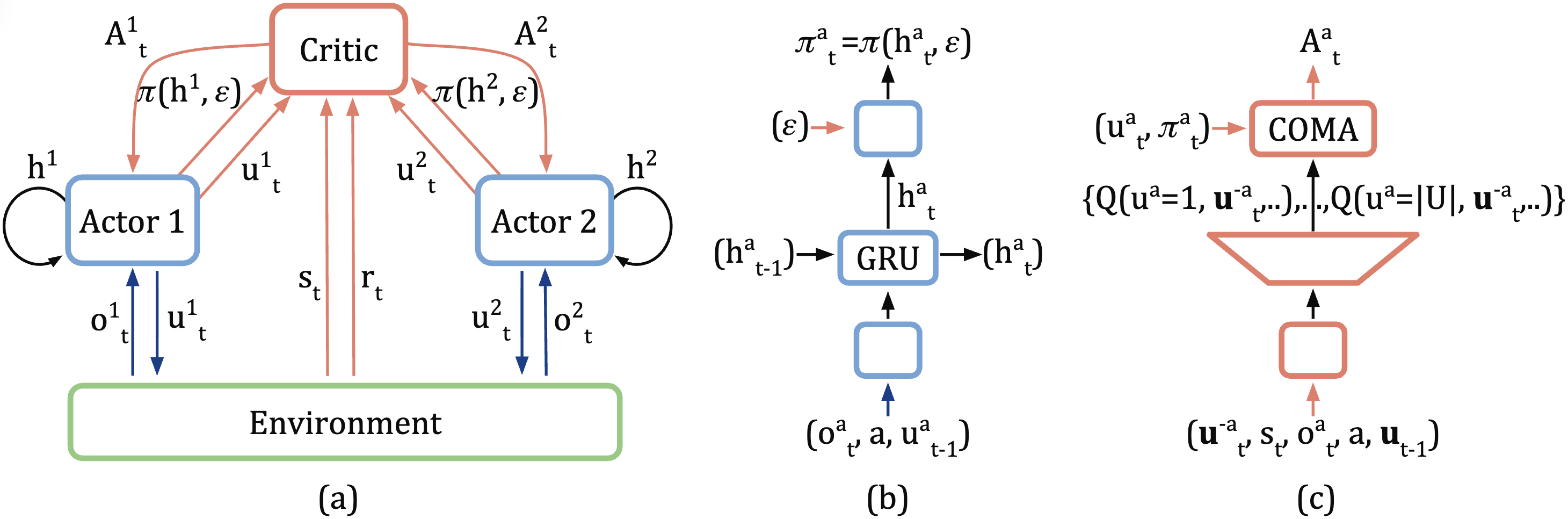
算法¶
训练 COMA 的完整算法在算法 1 中给出:

在 XuanCe 中运行 COMA¶
在 XuanCe 中运行 COMA 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 COMA:
import xuance
runner = xuance.get_runner(method='coma',
env='mpe',
env_id='simple_spread_v3',
is_test=False)
runner.run()
使用自定义配置运行¶
如果您想使用不同的配置运行 COMA,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 COMA:
import xuance
runner = xuance.get_runner(method='coma',
env='mpe',
env_id='simple_spread_v3',
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run()
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 COMA,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
coma_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 COMA:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import COMA_Agents
configs_dict = get_configs(file_dir="coma_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs)
Agent = COMA_Agents(config=configs, envs=envs)
Agent.train(configs.running_steps // configs.parallels)
Agent.save_model("final_train_model.pth")
Agent.finish() # 完成训练。
引用¶
@inproceedings{foerster2018counterfactual,
title={Counterfactual multi-agent policy gradients},
author={Foerster, Jakob and Farquhar, Gregory and Afouras, Triantafyllos and Nardelli, Nantas and Whiteson, Shimon},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
volume={32},
number={1},
year={2018}
}