欢迎来到“玄策”中文文档!¶






玄策 是一个深度强化学习(Deep Reinforcement Learning, DRL)开源算法库。“玄”字意为玄妙的,“策”意为策略。 在深度强化学习算法中,智能体通过和环境交互不断试错,最终学习出一个最优策略完成任务,而不需要对环境或动力学模型建立精确的模型,因此该算法库被称为“玄妙的策略”,故而取名“玄策”。
此外,虽然深度强化学习能够解决很多复杂的任务,但是在算法调试的过程中,深度神经网络和优化过程对超参数往往比较敏感。 对于某特殊结构的算法,要想调出一组最佳的超参数,往往需要开发人员进行大量的试错。 由于对超参数调试的方法主要以来开发人员的经验,难以总结出一条通用的规律,因此常被戏称为“玄学”。 而该算法库提供了大量目前主流的DRL算法,其实现过程易于理解,使得算法的复现不再玄学。
玄策强化学习算法库目前同时支持多种深度学习框架,包括
PyTorch ( ![]() ),
TensorFlow (
),
TensorFlow ( ![]() ),和
MindSpore (
),和
MindSpore ( ![]() )。并且支持CPU、GPU、Ascend运算,能够在Linux,Windows,MacOS等操作系统上运行。
)。并且支持CPU、GPU、Ascend运算,能够在Linux,Windows,MacOS等操作系统上运行。
为什么选择“玄策”?¶
XuanCe 旨在简化深度强化学习算法的实现与开发流程,帮助研究者快速掌握核心原理,从而高效投入算法设计与创新。 其主要特性如下:
高度模块化:采用模块化架构设计,具备优异的灵活性与可扩展性。
易学易用:上手简单,安装便捷,适合不同层次的用户使用。
灵活的模型集成:支持模型的自由组合与自定义配置,满足多样化需求。
丰富的算法库:内置多种强化学习算法,覆盖多类型任务场景。
多任务场景支持:同时支持深度强化学习(DRL)与多智能体强化学习(MARL)任务。
广泛的兼容性:兼容 PyTorch、TensorFlow、MindSpore 等框架,并可高效运行于 CPU、GPU 以及 Linux、Windows、macOS 等平台。
高性能计算:基于向量化环境实现快速执行与高效训练。
分布式训练:支持多 GPU 并行训练,便于大规模实验扩展。
自动化超参数调优:内置超参数自动搜索与优化功能。
可视化增强:集成 TensorBoard 与 Weights & Biases(wandb)等工具,提供直观、全面的训练过程可视化。
“玄策”算法列表¶
Value-based:
DQN: Deep Q-Network (DQN).DuelDQN: Dueling Deep Q-Network (Dueling DQN).NoisyDQN: DQN with Noisy Layers (Noisy DQN).DRQN: Deep Recurrent Q-Network (DRQN).C51: Categorical 51 DQN (C51).
Policy-based:
PG: Policy Gradient (PG).PPG: Phasic Policy Gradient (PPG).A2C: Advantage Actor Critic (A2C).SAC: Soft Actor-Critic (SAC).PPOCLIP: Proximal Policy Optimization with Clipped Objective (PPO-Clip).PPOKL: Proximal Policy Optimization with KL Divergence (PPO-KL).TD3: Twin Delayed Deep Deterministic Policy Gradient (TD3).
MARL-based:
IQL: Independent Q-Learning (IQL).QMIX: Q-Mixing Networks (QMIX).WQMIX: Weighted Q-Mixing Networks (WQMIX).QTRAN: Q-Transformation (QTRAN).IDDPG: Independent Deep Deterministic Policy Gradient (IDDPG).MADDPG: Multi-agent Deep Deterministic Policy Gradient (MADDPG).MFQ: Mean-Field Q-Learning (MFQ).MFAC: Mean-Field Actor-Critic (MFAC).MATD3: Multi-agent Twin Delayed Deep Deterministic Policy Gradient (MATD3).IC3Net: Individual Controlled Continuous Communication Model (IC3Net).
Model-based:
DreamerV2: Dreamer V2.DreamerV3: Dreamer V3.HarmonyDreamer: HarmonyDreamer.
Contrastive RL:
CURL: Contrastive Unsupervised Representations for Reinforcement Learning (CURL).SPR: Self-Predictive Representations for Reinforcement Learning (SPR).
Offline RL:
“玄策”整体框架¶
“玄策”的整体框架如下图所示.
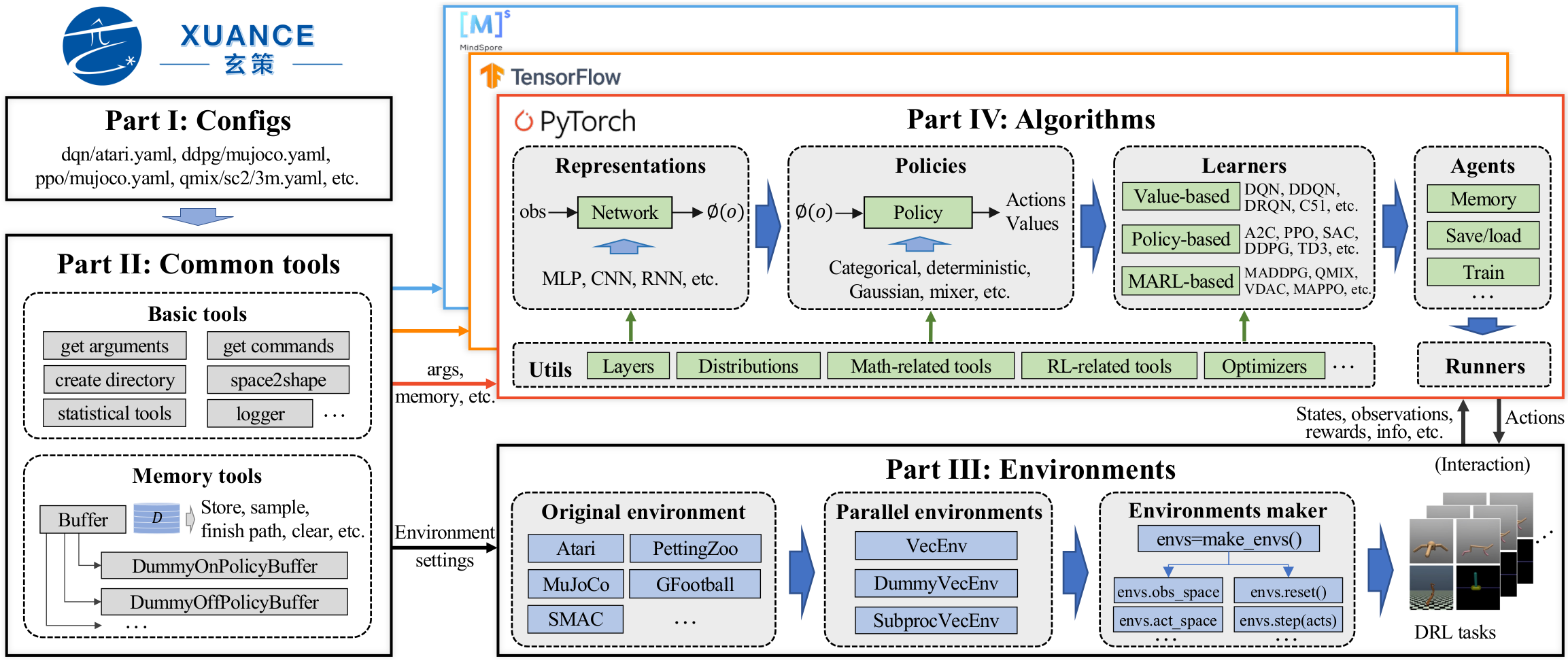
玄策框架主要由以下四个部分构成:
第一部分: Configs. 环境参数、算法超参数、模型规模、训练参数等配置信息;
第二部分: Common Tools. 通用工具,包含经验回放池等模块;
第三部分: Environments. 环境模块,包含玄策的环境封装,向量化环境等工具;
第四部分: Algorithms. 算法模块,包含表征器、策略、学习器、智能体等模块。
“玄策”适用人群¶
“玄策”的适用人群包括但不限于:
研究人员:深度强化学习方向的研究人员
开发人员:深度强化学习算法开发人员
学生、初学者:深度强化学习方向的学生、入门该方向的初学者
AI从业者:从事 AI 行业,特别是对 AI 决策领域感兴趣的从业者
文档目录¶
教程
接口: