Tuning Tools¶
HyperParameters Tuning for A Single Objective¶
We support users in automatically tuning hyperparameters using our core APIs: HyperParameterTuner and set_hyperparameters.
We can use the optuna.visualization.plot_optimization_history API to plot the visualize the optimization history.
from xuance.common import HyperParameterTuner, set_hyperparameters
from optuna.visualization import plot_optimization_history
tuner = HyperParameterTuner(method='dqn',
config_path='./examples/dqn/dqn_configs/dqn_cartpole.yaml',
running_steps=1000,
test_episodes=2)
Next, users should select the hyperparameters they wish to tune by calling the select_hyperparameter method.
selected_hyperparameters = tuner.select_hyperparameter(['learning_rate'])
If you want to override the default parameter ranges, you can use the set_hyperparameters method.
overrides = {
'learning_rate': [0.001, 0.0001, 0.00001]
}
selected_hyperparameters = set_hyperparameters(selected_hyperparameters, overrides)
Finally, you can initiate the hyperparameter tuning process by using the tune method.
study = tuner.tune(selected_hyperparameters, n_trials=30, pruner=None)
fig = plot_optimization_history(study)
fig.show()
Output:
[I 2025-01-27 22:03:38,163] A new study created in memory with name: no-name-379963bc-4018-4689-9717-5e0b9309b01a
100%|██████████| 10000/10000 [00:08<00:00, 1124.88it/s]
[I 2025-01-27 22:04:04,359] Trial 0 finished with value: 404.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9767360777435363}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:12<00:00, 785.41it/s]
[I 2025-01-27 22:04:19,834] Trial 1 finished with value: 101.5 and parameters: {'learning_rate': 0.001, 'gamma': 0.9172532769498477}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:11<00:00, 904.99it/s]
[I 2025-01-27 22:04:38,108] Trial 2 finished with value: 228.5 and parameters: {'learning_rate': 0.001, 'gamma': 0.9873376045457305}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:12<00:00, 807.38it/s]
[I 2025-01-27 22:04:52,825] Trial 3 finished with value: 158.5 and parameters: {'learning_rate': 0.001, 'gamma': 0.9702251977609887}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:13<00:00, 742.27it/s]
[I 2025-01-27 22:05:06,553] Trial 4 finished with value: 9.0 and parameters: {'learning_rate': 1e-05, 'gamma': 0.9554481153907192}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:11<00:00, 853.94it/s]
[I 2025-01-27 22:05:22,542] Trial 5 finished with value: 286.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9302372638242611}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:15<00:00, 646.94it/s]
[I 2025-01-27 22:05:41,567] Trial 6 finished with value: 227.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9269076358553893}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:13<00:00, 748.87it/s]
[I 2025-01-27 22:05:58,529] Trial 7 finished with value: 127.5 and parameters: {'learning_rate': 0.001, 'gamma': 0.9549905416387551}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:14<00:00, 706.51it/s]
[I 2025-01-27 22:06:18,365] Trial 8 finished with value: 330.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9762353810142133}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:14<00:00, 700.27it/s]
[I 2025-01-27 22:06:33,151] Trial 9 finished with value: 15.0 and parameters: {'learning_rate': 1e-05, 'gamma': 0.9037880376363823}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:11<00:00, 842.43it/s]
[I 2025-01-27 22:06:48,570] Trial 10 finished with value: 128.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9867610541439971}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:12<00:00, 807.62it/s]
[I 2025-01-27 22:07:05,940] Trial 11 finished with value: 184.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9684239534732142}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:12<00:00, 823.51it/s]
[I 2025-01-27 22:07:25,303] Trial 12 finished with value: 268.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.970551827128961}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:12<00:00, 769.71it/s]
[I 2025-01-27 22:07:45,624] Trial 13 finished with value: 264.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.950334691240254}. Best is trial 0 with value: 404.5.
100%|██████████| 10000/10000 [00:10<00:00, 936.89it/s]
[I 2025-01-27 22:08:01,894] Trial 14 finished with value: 500.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9794002862955594}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:10<00:00, 917.90it/s]
[I 2025-01-27 22:08:16,754] Trial 15 finished with value: 280.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9806848983425671}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:14<00:00, 696.63it/s]
[I 2025-01-27 22:08:31,386] Trial 16 finished with value: 10.5 and parameters: {'learning_rate': 1e-05, 'gamma': 0.961159041707934}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:11<00:00, 844.49it/s]
[I 2025-01-27 22:08:47,506] Trial 17 finished with value: 296.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9419642492222219}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:11<00:00, 849.85it/s]
[I 2025-01-27 22:09:01,995] Trial 18 finished with value: 185.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9411086355869422}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:12<00:00, 821.68it/s]
[I 2025-01-27 22:09:14,976] Trial 19 finished with value: 29.5 and parameters: {'learning_rate': 1e-05, 'gamma': 0.9650205053215359}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:12<00:00, 831.33it/s]
[I 2025-01-27 22:09:32,670] Trial 20 finished with value: 203.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9803579334603305}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:11<00:00, 862.28it/s]
[I 2025-01-27 22:09:46,772] Trial 21 finished with value: 172.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9774744793615214}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:10<00:00, 925.57it/s]
[I 2025-01-27 22:10:03,554] Trial 22 finished with value: 500.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9778899955666167}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:13<00:00, 727.49it/s]
[I 2025-01-27 22:10:30,680] Trial 23 finished with value: 497.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9897469689147355}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:10<00:00, 941.68it/s]
[I 2025-01-27 22:10:47,279] Trial 24 finished with value: 500.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9852452395066185}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:10<00:00, 948.01it/s]
[I 2025-01-27 22:11:01,500] Trial 25 finished with value: 266.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9607319249768325}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:15<00:00, 643.80it/s]
[I 2025-01-27 22:11:26,484] Trial 26 finished with value: 375.5 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9835921209233993}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:11<00:00, 881.32it/s]
[I 2025-01-27 22:11:39,775] Trial 27 finished with value: 135.0 and parameters: {'learning_rate': 0.0001, 'gamma': 0.9734922001537907}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:13<00:00, 714.37it/s]
[I 2025-01-27 22:11:57,328] Trial 28 finished with value: 233.5 and parameters: {'learning_rate': 0.001, 'gamma': 0.9890643784612279}. Best is trial 14 with value: 500.0.
100%|██████████| 10000/10000 [00:13<00:00, 736.18it/s]
[I 2025-01-27 22:12:11,748] Trial 29 finished with value: 23.0 and parameters: {'learning_rate': 1e-05, 'gamma': 0.9763628568024245}. Best is trial 14 with value: 500.0.
Best hyper-parameters: {'learning_rate': 0.0001, 'gamma': 0.9794002862955594}
Best value: 500.0
Process finished with exit code 0
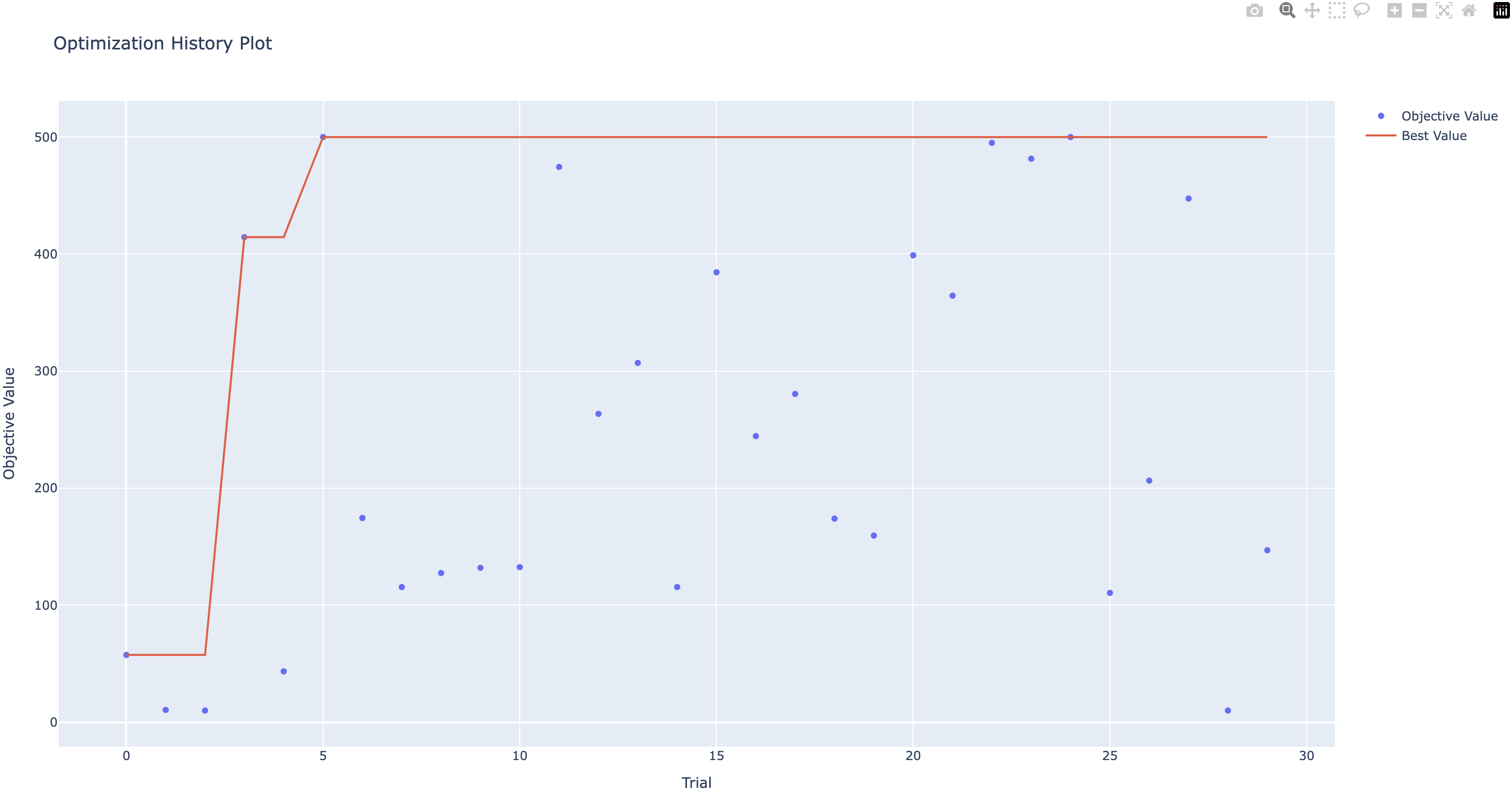
Full code: tune_dqn.py
Hyper-Parameters Tuning for Multi-Objective¶
We also support users in automatically tuning hyperparameters by optimizing multiple objectives.
The core APIs: MultiObjectiveTuner and set_hyperparameters.
We can use the optuna.visualization.plot_pareto_front API to plot the visualize the optimization history.
Then, select the hyperparameters by calling the select_hyperparameter method.
selected_hyperparameters = tuner.select_hyperparameter(['learning_rate', 'gamma'])
Similarly, if you want to override the default parameter ranges, you can use the set_hyperparameters method.
overrides = {
'learning_rate': [0.001, 0.0001, 0.00001]
}
selected_hyperparameters = set_hyperparameters(selected_hyperparameters, overrides)
Finally, you can initiate the hyperparameter tuning process by using the tune method,
and select the objectives to be optimized.
study = tuner.tune(selected_hyperparameters, n_trials=30, pruner=None, directions=['maximize', 'maximize'],
selected_objectives=['test_score', 'Qloss'])
fig = plot_pareto_front(study, target_names=["scores", "loss"])
fig.show()
Output:
[I 2025-01-27 18:43:35,345] A new study created in memory with name: no-name-6c89b40f-6439-4a4e-9a5f-296dcd3fc6ef
100%|██████████| 10000/10000 [00:09<00:00, 1002.66it/s]
[I 2025-01-27 18:43:50,053] Trial 0 finished with values: [10.5, 0.5725632309913635] and parameters: {'learning_rate': 1e-05, 'gamma': 0.983794359786884}.
100%|██████████| 10000/10000 [00:09<00:00, 1106.70it/s]
[I 2025-01-27 18:44:01,006] Trial 1 finished with values: [131.0, 0.027604958042502403] and parameters: {'learning_rate': 0.001, 'gamma': 0.9529332636959564}.
100%|██████████| 10000/10000 [00:09<00:00, 1036.33it/s]
[I 2025-01-27 18:44:16,663] Trial 2 finished with values: [206.0, 0.4492032527923584] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9061580755417351}.
100%|██████████| 10000/10000 [00:13<00:00, 729.90it/s]
[I 2025-01-27 18:44:30,626] Trial 3 finished with values: [10.5, 0.3588852286338806] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9327088919334499}.
100%|██████████| 10000/10000 [00:11<00:00, 842.90it/s]
[I 2025-01-27 18:44:42,749] Trial 4 finished with values: [9.0, 0.4106123447418213] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9506806713731859}.
100%|██████████| 10000/10000 [00:10<00:00, 910.86it/s]
[I 2025-01-27 18:44:54,009] Trial 5 finished with values: [10.5, 0.44131147861480713] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9621350784320322}.
100%|██████████| 10000/10000 [00:09<00:00, 1057.79it/s]
[I 2025-01-27 18:45:07,593] Trial 6 finished with values: [150.5, 0.01387395616620779] and parameters: {'learning_rate': 0.001, 'gamma': 0.9014830541169255}.
100%|██████████| 10000/10000 [00:12<00:00, 815.04it/s]
[I 2025-01-27 18:45:31,819] Trial 7 finished with values: [453.5, 0.6781903505325317] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9276574042604141}.
100%|██████████| 10000/10000 [00:11<00:00, 885.27it/s]
[I 2025-01-27 18:45:45,783] Trial 8 finished with values: [181.0, 0.041073016822338104] and parameters: {'learning_rate': 0.001, 'gamma': 0.9542330504397663}.
100%|██████████| 10000/10000 [00:15<00:00, 666.38it/s]
[I 2025-01-27 18:46:01,048] Trial 9 finished with values: [9.0, 0.5510137677192688] and parameters: {'learning_rate': 1e-05, 'gamma': 0.970858398387788}.
100%|██████████| 10000/10000 [00:13<00:00, 763.90it/s]
[I 2025-01-27 18:46:14,408] Trial 10 finished with values: [10.0, 0.2025887668132782] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9040287898164331}.
100%|██████████| 10000/10000 [00:10<00:00, 976.03it/s]
[I 2025-01-27 18:46:30,968] Trial 11 finished with values: [398.0, 1.1926697492599487] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9799375678502391}.
100%|██████████| 10000/10000 [00:12<00:00, 813.99it/s]
[I 2025-01-27 18:46:48,357] Trial 12 finished with values: [189.5, 0.24833709001541138] and parameters: {'learning_rate': 0.001, 'gamma': 0.9884084202442817}.
100%|██████████| 10000/10000 [00:12<00:00, 801.97it/s]
[I 2025-01-27 18:47:07,514] Trial 13 finished with values: [457.5, 0.10496468096971512] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9433082393803593}.
100%|██████████| 10000/10000 [00:14<00:00, 696.03it/s]
[I 2025-01-27 18:47:22,285] Trial 14 finished with values: [18.0, 1.1194093227386475] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9232300611179586}.
100%|██████████| 10000/10000 [00:10<00:00, 987.71it/s]
[I 2025-01-27 18:47:37,934] Trial 15 finished with values: [358.5, 0.46146366000175476] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9103890955570757}.
100%|██████████| 10000/10000 [00:11<00:00, 854.48it/s]
[I 2025-01-27 18:47:54,490] Trial 16 finished with values: [173.0, 0.013818178325891495] and parameters: {'learning_rate': 0.001, 'gamma': 0.9375222854512043}.
100%|██████████| 10000/10000 [00:12<00:00, 806.04it/s]
[I 2025-01-27 18:48:10,633] Trial 17 finished with values: [136.0, 0.04661601036787033] and parameters: {'learning_rate': 0.001, 'gamma': 0.9452712826961123}.
100%|██████████| 10000/10000 [00:11<00:00, 893.24it/s]
[I 2025-01-27 18:48:27,570] Trial 18 finished with values: [209.5, 0.31870752573013306] and parameters: {'learning_rate': 0.0001, 'gamma': 0.9174535109799054}.
100%|██████████| 10000/10000 [00:10<00:00, 945.54it/s]
[I 2025-01-27 18:48:39,971] Trial 19 finished with values: [127.5, 0.027894726023077965] and parameters: {'learning_rate': 0.001, 'gamma': 0.9010656143920244}.
100%|██████████| 10000/10000 [00:15<00:00, 654.24it/s]
[I 2025-01-27 18:48:55,531] Trial 20 finished with values: [10.5, 0.3386041522026062] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9512151767613496}.
100%|██████████| 10000/10000 [00:15<00:00, 626.52it/s]
[I 2025-01-27 18:49:11,774] Trial 21 finished with values: [10.5, 0.5792076587677002] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9810109046704306}.
100%|██████████| 10000/10000 [00:14<00:00, 693.50it/s]
[I 2025-01-27 18:49:29,804] Trial 22 finished with values: [132.5, 0.008449300192296505] and parameters: {'learning_rate': 0.001, 'gamma': 0.9389305792145501}.
100%|██████████| 10000/10000 [00:10<00:00, 942.96it/s]
[I 2025-01-27 18:49:42,003] Trial 23 finished with values: [105.5, 0.1087193712592125] and parameters: {'learning_rate': 0.001, 'gamma': 0.9388598176875353}.
100%|██████████| 10000/10000 [00:11<00:00, 847.65it/s]
[I 2025-01-27 18:49:59,865] Trial 24 finished with values: [214.0, 0.020569007843732834] and parameters: {'learning_rate': 0.001, 'gamma': 0.910639670345965}.
100%|██████████| 10000/10000 [00:12<00:00, 798.35it/s]
[I 2025-01-27 18:50:14,680] Trial 25 finished with values: [160.5, 0.018472230061888695] and parameters: {'learning_rate': 0.001, 'gamma': 0.9190252166458316}.
100%|██████████| 10000/10000 [00:12<00:00, 825.27it/s]
[I 2025-01-27 18:50:29,097] Trial 26 finished with values: [158.0, 0.017763447016477585] and parameters: {'learning_rate': 0.001, 'gamma': 0.924026288312545}.
100%|██████████| 10000/10000 [00:11<00:00, 853.41it/s]
[I 2025-01-27 18:50:51,230] Trial 27 finished with values: [362.5, 0.6701189875602722] and parameters: {'learning_rate': 0.001, 'gamma': 0.9829385756798945}.
100%|██████████| 10000/10000 [00:12<00:00, 808.29it/s]
[I 2025-01-27 18:51:03,855] Trial 28 finished with values: [9.0, 1.8073229789733887] and parameters: {'learning_rate': 1e-05, 'gamma': 0.986664209966707}.
100%|██████████| 10000/10000 [00:12<00:00, 811.24it/s]
[I 2025-01-27 18:51:16,440] Trial 29 finished with values: [9.0, 0.44973304867744446] and parameters: {'learning_rate': 1e-05, 'gamma': 0.9791446853655159}.
Number of finished trials: 30
Process finished with exit code 0
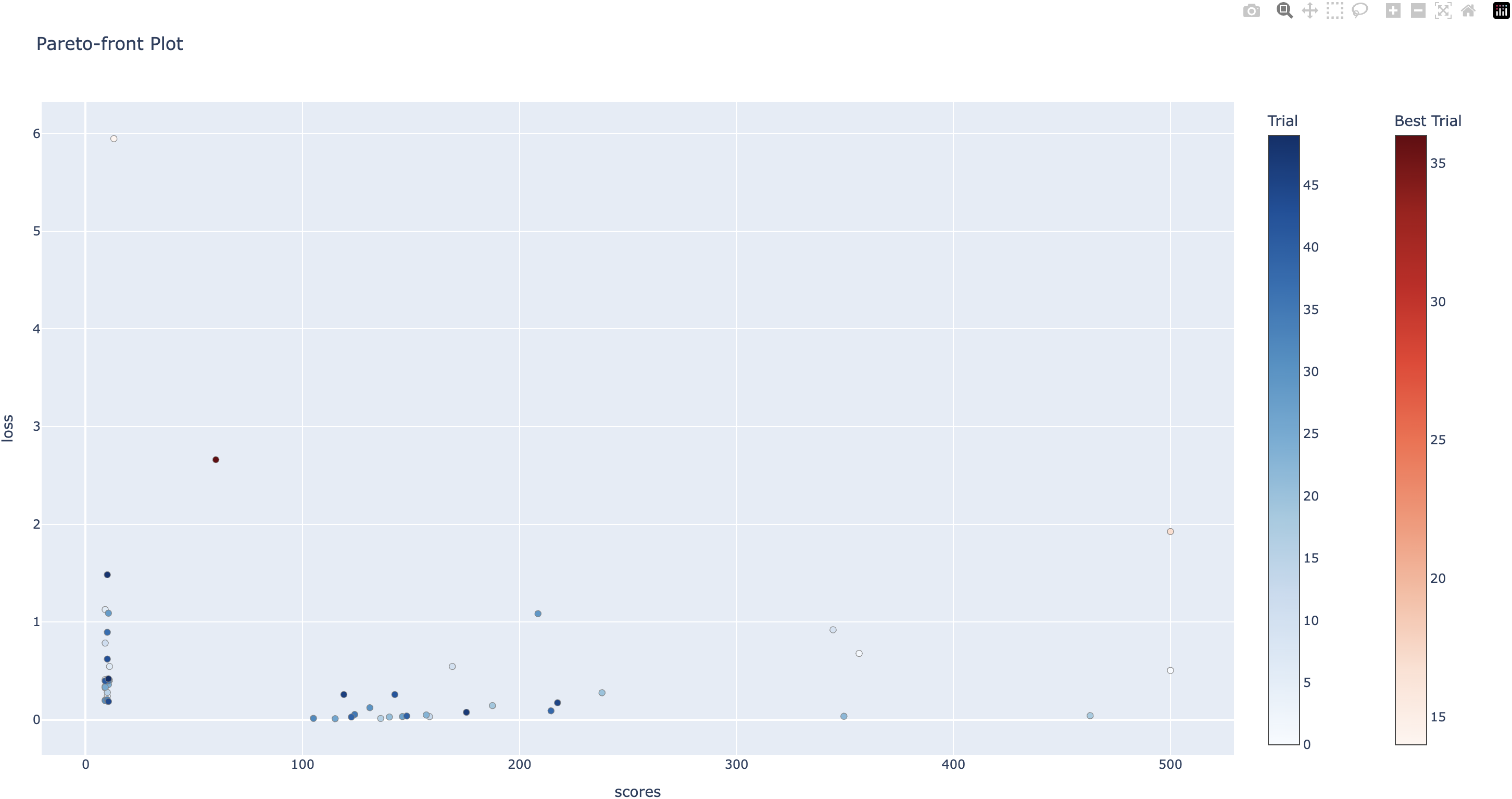
Full code: tune_dqn_multiobjective.py
APIs¶
- class xuance.common.tuning_tools.AlgorithmHyperparametersRegistry[源代码]¶
基类:
objectA registry for managing hyperparameters of different algorithms.
This class allows for the registration of algorithms along with their corresponding hyperparameters. It provides methods to retrieve hyperparameters for a specific algorithm and to list all registered algorithms.
- _registry¶
A class-level dictionary mapping algorithm names to their list of hyperparameters.
- Type:
dict
- classmethod get_hyperparameters(algorithm_name: str) List[Hyperparameter][源代码]¶
Retrieve the list of hyperparameters for a given algorithm.
- 参数:
algorithm_name (str) – The name of the algorithm whose hyperparameters are to be retrieved.
- 返回:
- A list of Hyperparameter instances associated with the specified algorithm.
Returns an empty list if the algorithm is not registered.
- 返回类型:
List[Hyperparameter]
示例
>>> hyperparams = AlgorithmHyperparametersRegistry.get_hyperparameters("DQN") >>> for hp in hyperparams: ... print(hp.name, hp.type) learning_rate float gamma float
- classmethod list_algorithms() List[str][源代码]¶
List all registered algorithms.
- 返回:
A list of all algorithm names that have been registered in the registry.
- 返回类型:
List[str]
示例
>>> algorithms = AlgorithmHyperparametersRegistry.list_algorithms() >>> print(algorithms) ['DQN', 'A2C', 'SAC']
- classmethod register_algorithm(algorithm_name: str, hyperparameters: List[Hyperparameter])[源代码]¶
Register an algorithm along with its hyperparameters.
This method adds an algorithm and its associated hyperparameters to the registry. If the algorithm already exists, its hyperparameters will be updated.
- 参数:
algorithm_name (str) – The name of the algorithm to register.
hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances defining the algorithm’s hyperparameters.
示例
>>> hyperparams = [ ... Hyperparameter(name="learning_rate", type="float", distribution=(1e-5, 1e-2), log=True, default=1e-3), ... Hyperparameter(name="gamma", type="float", distribution=(0.85, 0.99), log=False, default=0.99), ... ] >>> AlgorithmHyperparametersRegistry.register_algorithm("DQN", hyperparams)
- class xuance.common.tuning_tools.HyperParameterTuner(algo: str, config_path: str, running_steps: int | None = None, test_episodes: int | None = None)[源代码]¶
基类:
objectA class to facilitate automatic hyperparameter tuning for reinforcement learning algorithms using Optuna.
The HyperParameterTuner class provides methods to list, select, and tune hyperparameters for a specified algorithm within the XuanCe framework. It integrates with Optuna to perform efficient hyperparameter optimization.
- algo¶
The name of the algorithm (e.g., ‘dqn’).
- Type:
str
- config_path¶
The path to the configuration YAML file.
- Type:
str
- running_steps¶
Number of steps to run a trial. Defaults to the value in the configuration.
- Type:
Optional[int]
- test_episodes¶
Number of episodes to evaluate the agent’s policy. Defaults to the value in the configuration.
- Type:
Optional[int]
- eval_env_fn()[源代码]¶
Create the environment for evaluating the agent’s policy.
This method configures a single (vectorized) environment instance used solely for evaluating the performance of the trained agent.
- 返回:
An instance of the environment configured for evaluation.
- 返回类型:
Vectorized Environment
- list_hyperparameters() List[Hyperparameter][源代码]¶
List the hyperparameters of the selected algorithm.
This method retrieves all registered hyperparameters for the algorithm specified during the initialization of the tuner.
- 返回:
A list of Hyperparameter instances associated with the selected algorithm.
- 返回类型:
List[Hyperparameter]
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> hyperparams = tuner.list_hyperparameters() >>> for hp in hyperparams: ... print(hp.name, hp.type) learning_rate float gamma float
- objective(trail: optuna.trial, selected_hyperparameters: List[Hyperparameter]) float[源代码]¶
Define the objective function for Optuna optimization.
This function builds the search space, updates the configuration with suggested hyperparameters, initializes the environment and agent, trains the agent, evaluates its performance, and returns the mean score as the objective value.
- 参数:
trial (optuna.trial.Trial) – The Optuna trial object used for suggesting hyperparameter values.
selected_hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances selected for tuning.
- 返回:
The mean score obtained from evaluating the agent’s policy.
- 返回类型:
float
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> hyperparams = tuner.select_hyperparameter(['learning_rate', 'gamma']) >>> study = optuna.create_study(direction="maximize") >>> study.optimize(lambda trial: tuner.objective(trial, hyperparams), n_trials=10)
- select_hyperparameter(hyperparameter_names: List[str]) List[Hyperparameter][源代码]¶
Select specific hyperparameters for tuning based on their names.
This method filters the list of all hyperparameters to include only those specified by the user. It raises an error if no hyperparameters are selected.
- 参数:
hyperparameter_names (List[str]) – A list of hyperparameter names to select for tuning.
- 返回:
A list of selected Hyperparameter instances.
- 返回类型:
List[Hyperparameter]
- 抛出:
ValueError – If no hyperparameters are selected for tuning.
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> selected = tuner.select_hyperparameter(['learning_rate', 'gamma']) >>> for hp in selected: ... print(hp.name, hp.type) learning_rate float gamma float
- tune(selected_hyperparameters: List[Hyperparameter], n_trials: int = 1, pruner: optuna.pruners.BasePruner | None = None, direction: str = 'maximize') optuna.study.Study[源代码]¶
Start the hyperparameter tuning process.
This method initializes an Optuna study, defines the objective function wrapper, and begins the optimization process to search for the best hyperparameter values.
- 参数:
selected_hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances selected for tuning.
n_trials (int, optional) – The number of trials to run during optimization. Defaults to 1.
pruner (Optional[optuna.pruners.BasePruner], optional) – An Optuna pruner to terminate unpromising trials early. Defaults to None.
direction (str) – The optimization directions. Defaults to “maximize”.
- 返回:
The Optuna study object containing the results of the optimization.
- 返回类型:
optuna.study.Study
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> hyperparams = tuner.select_hyperparameter(['learning_rate', 'gamma']) >>> study = tuner.tune(selected_hyperparameters=hyperparams, n_trials=30) >>> print(study.best_params)
- class xuance.common.tuning_tools.Hyperparameter(name: str, type: str, distribution: List[Any] | tuple, log: bool = False, default: Any | None = None)[源代码]¶
基类:
objectRepresents a hyperparameter for algorithm tuning.
This dataclass defines the structure of a hyperparameter, including its name, type, distribution, whether it should be sampled on a logarithmic scale, and its default value.
- name¶
The name of the hyperparameter.
- Type:
str
- type¶
The type of the hyperparameter. Supported types include ‘int’, ‘float’, and ‘categorical’.
- Type:
str
- distribution¶
The possible values or range for the hyperparameter. - For ‘categorical’ types, this should be a list of possible values. - For ‘int’ and ‘float’ types, this should be a tuple defining the range (min, max).
- Type:
Union[List[Any], tuple]
- log¶
Indicates whether the hyperparameter should be sampled on a logarithmic scale. This is typically used for hyperparameters like learning rates that span several orders of magnitude. Defaults to False.
- Type:
bool, optional
- default¶
The default value of the hyperparameter if no tuning is performed. This provides a fallback value to ensure the algorithm can run with standard settings. Defaults to None.
- Type:
Optional[Any], optional
- default: Any | None = None¶
- distribution: List[Any] | tuple¶
- log: bool = False¶
- name: str¶
- type: str¶
- class xuance.common.tuning_tools.MultiObjectiveTuner(**kwargs)[源代码]¶
-
A class to facilitate multi-objective hyperparameter tuning for reinforcement learning algorithms using Optuna.
- objective(trial: optuna.trial, selected_hyperparameters: List[Hyperparameter], selected_objectives: List[str] | None = None) float[源代码]¶
Define the objective function for Optuna optimization.
This function builds the search space, updates the configuration with suggested hyperparameters, initializes the environment and agent, trains the agent, evaluates its performance, and returns the mean score as the objective value.
- 参数:
trial (optuna.trial.Trial) – The Optuna trial object used for suggesting hyperparameter values.
selected_hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances selected for tuning.
selected_objectives (List[str]) – A list of objectives selected for tuning.
- 返回:
The mean score obtained from evaluating the agent’s policy.
- 返回类型:
float
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> hyperparams = tuner.select_hyperparameter(['learning_rate', 'gamma']) >>> study = optuna.create_study(direction="maximize") >>> study.optimize(lambda trial: tuner.objective(trial, hyperparams), n_trials=10)
- tune(selected_hyperparameters: List[Hyperparameter], n_trials: int = 1, pruner: optuna.pruners.BasePruner | None = None, directions: list | None = None, selected_objectives: List[str] | None = None) optuna.study.Study[源代码]¶
Start the hyperparameter tuning process.
This method initializes an Optuna study, defines the objective function wrapper, and begins the optimization process to search for the best hyperparameter values.
- 参数:
selected_hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances selected for tuning.
n_trials (int, optional) – The number of trials to run during optimization. Defaults to 1.
pruner (Optional[optuna.pruners.BasePruner], optional) – An Optuna pruner to terminate unpromising trials early. Defaults to None.
directions – The optimization directions. Default is None.
selected_objectives (List[str]) – A list of objectives selected for tuning.
- 返回:
The Optuna study object containing the results of the optimization.
- 返回类型:
optuna.study.Study
示例
>>> tuner = HyperParameterTuner(algo='dqn', config_path='config.yaml') >>> hyperparams = tuner.select_hyperparameter(['learning_rate', 'gamma']) >>> study = tuner.tune(selected_hyperparameters=hyperparams, n_trials=30, selected_objectives=['test_score', 'loss']) >>> print(study.best_params)
- xuance.common.tuning_tools.build_search_space(trial: optuna.trial, hyperparameters: List[Hyperparameter]) dict[源代码]¶
Build the search space for tuning hyperparameters using Optuna.
This function iterates over a list of hyperparameters and defines the search space based on their type and distribution. It supports categorical, float (both uniform and log-uniform), and integer hyperparameters.
- 参数:
trial (optuna.trial.Trial) – The Optuna trial object used to suggest hyperparameter values.
hyperparameters (List[Hyperparameter]) – A list of Hyperparameter instances defining the hyperparameters to tune.
- 返回:
A dictionary mapping hyperparameter names to their suggested values for the current trial.
- 返回类型:
dict
- 抛出:
ValueError – If an unsupported hyperparameter type is encountered.
示例
>>> hyperparams = [ ... Hyperparameter(name="learning_rate", type="float", distribution=(1e-5, 1e-2), log=True, default=1e-3), ... Hyperparameter(name="batch_size", type="int", distribution=[32, 64, 128, 256], default=64), ... ] >>> trial = optuna.trial.create_trial() >>> search_space = build_search_space(trial, hyperparams)
- xuance.common.tuning_tools.set_hyperparameters(hyperparameters: List[Hyperparameter], overrides: dict) List[Hyperparameter][源代码]¶
Override the distributions of specified hyperparameters.
This function updates the distribution of hyperparameters based on the provided overrides. It ensures that the new distribution is either a tuple or a list. If an unsupported distribution type is provided, it raises a ValueError.
- 参数:
hyperparameters (List[Hyperparameter]) – The list of Hyperparameter instances to override.
overrides (dict) – A dictionary mapping hyperparameter names to their new distributions.
- 返回:
The updated list of Hyperparameter instances with overridden distributions.
- 返回类型:
List[Hyperparameter]
- 抛出:
ValueError – If an unsupported distribution type is provided for any hyperparameter.
示例
>>> hyperparams = [ ... Hyperparameter(name="learning_rate", type="float", distribution=(1e-5, 1e-2), log=True, default=1e-3), ... Hyperparameter(name="batch_size", type="int", distribution=[32, 64, 128, 256], default=64), ... ] >>> overrides = { ... "learning_rate": [0.001, 0.0001, 0.00001], ... } >>> updated_hyperparams = set_hyperparameters(hyperparams, overrides)