Q-变换 (QTRAN)¶
论文链接: http://proceedings.mlr.press/v97/son19a.html.
QTRAN 是多智能体强化学习(MARL)中提出的一种价值分解方法,用于克服经典算法的结构局限性。与 QMIX 等依赖单调性约束的算法不同,QTRAN 创新性地引入了变换的联合动作-价值函数,使其能够表示更广泛的协作策略。该算法在非单调任务(如协作捕食)中表现出色,显著优于 QMIX 等主流算法,并突出了其在复杂多智能体协作中的强大潜力。
下表列出了 QTRAN 算法的一些一般特性:
QTRAN 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
❌ |
评估策略与目标策略相同。 |
异策略 |
✅ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
❌ |
处理连续动作空间。 |
1. 研究背景与动机¶
之前介绍的 VDN、QMIX 和 WQMIX 算法都是用于协作多智能体强化学习(MARL)任务的基于价值的方法。这些算法本质上旨在找到满足以下公式所描述关系的分布式最优策略:
这里,\(Q_{jt}\) 表示联合动作-价值函数,\(Q_i\) 表示智能体 \(i\) 的价值函数。在本文中,作者将公式 (1) 中的关系定义为**IGM(个体-全局-最大)**条件。
为了满足 IGM 条件,VDN 直接将价值函数分解为”加法形式”:
从公式 (2) 可以推导出 \(\frac{\partial Q_{jt}(\boldsymbol{\tau}, \mathbf{u})}{\partial Q_i(\tau_i, u_i)} \equiv 1, \quad \forall i \in \mathcal{N}.\),这表明满足公式 (2) 足以满足 IGM 条件。
然而,QMIX 认为 VDN 的方法过于受限,无法有效拟合许多复杂函数。因此,QMIX 提出了更一般的单调性条件:
QMIX 认为满足公式 (3) 足以满足 IGM 条件。
确实,公式 (2) 是公式 (3) 的充分条件,但与此同时,公式 (3) 也是公式 (1) 的充分条件。换句话说,两者都不是 IGM 条件的必要条件!因此,对于某些具有非单调回报的协作问题,VDN 和 QMIX 的函数逼近能力变得有限——这与 WQMIX 算法背后的研究动机一致。
因此,为了解决这个问题,作者提出了 QTRAN 算法,并声称它可以分解任何可分解的任务,而不受公式 (2) 和 (3) 的约束。
2. 算法方法¶
作者的核心思想是将原始联合价值函数 \(Q_{jt}(\boldsymbol{\tau}, \mathbf{u})\) 映射到新的价值函数 \(Q'_{jt}(\boldsymbol{\tau}, \mathbf{u})\),使得这两个函数的最优联合动作等价。这允许我们通过分解 \(Q'_{jt}\) 来获得个体价值函数 \([Q_i]\),同时也建立 \(Q'_{jt}\) 和 \(Q_{jt}\) 之间的关系以确保全局最优性。
显然,这样的映射不能是任意的。为了保证全局最优性,作者首先提出了价值函数分解必须满足的条件。
2.1 价值函数分解的条件¶
设 \(\bar{u}_i = \arg \max_{u_i} Q_i(\tau_i, u_i)\) 表示智能体 \(i\) 的最优局部动作;\(\bar{\mathbf{u}} = [\bar{u}_i]_{i=1}^N\) 表示联合最优局部动作;\(\mathbf{Q} = [Q_i]_{i=1}^N \in \mathbb{R}^N\) 表示联合价值函数向量。作者提供了以下结论:
定理 1.
当 \(Q_{jt}(\boldsymbol{\tau}, \mathbf{u})\) 和 \([Q_i(\tau_i, u_i)]_{i=1}^N\) 满足以下关系:
其中 \(V_{jt}(\boldsymbol{\tau}) = \max_{\mathbf{u}} Q_{jt}(\boldsymbol{\tau}, \mathbf{u}) - \sum_{i=1}^N Q_i(\tau_i, \bar{u}_i)\),那么联合动作-价值函数 \(Q_{jt}(\boldsymbol{\tau}, \mathbf{u})\) 可以分解为 \([Q_i(\tau_i, u_i)]_{i=1}^N\)。
定理 1 表明,只要满足公式 (4) 中的关系,就可以满足 IGM 条件。以下分析探讨了这个定理的数学逻辑,以帮助深入理解(详细证明,请参阅原文附录)。
充分性:
我们可以将 \(Q_{jt}\) 表达式的左侧重写为:
观察到当 \(\mathbf{u} = \bar{\mathbf{u}}\) 时,我们有 \(\max_{u_i} Q_i(\tau_i, u_i) - Q_i(\tau_i, u_i) = 0\)。在这种情况下,如果 \(\delta = 0\),则意味着 \(\max_{\mathbf{u}} Q_{jt}(\boldsymbol{\tau}, \mathbf{u}) - Q_{jt}(\boldsymbol{\tau}, \bar{\mathbf{u}}) = 0\)。因此,IGM 条件得到满足。
当 \(\mathbf{u} \neq \bar{\mathbf{u}}\) 时,如果 \(\delta \geq 0\),则意味着:
因此,\(\max_{\mathbf{u}} Q_{jt}(\boldsymbol{\tau}, \mathbf{u}) \geq Q_{jt}(\boldsymbol{\tau}, \mathbf{u})\),意味着未达到最优。换句话说,全局价值函数仅在 \(\mathbf{u} = \bar{\mathbf{u}}\) 时达到最优。
从这个角度来看,这个条件是相当充分的。但是,它是必要的吗?
必要性:
作者在论文中指出,在仿射变换 \(\phi(\mathbf{Q}) = {A} \cdot \mathbf{Q} + {B}\) 下,公式 (4) 是必要的。这里,
\({A} = [a_{ii}]\) 是所有元素为正的对角矩阵,\({B} = [b_i]\) 是偏置项。
这意味着只要 IGM 条件成立,就必定存在一个仿射变换 \(\phi\),在适当拉伸和缩放分解的价值函数向量 \(\mathbf{Q}\) 后(将 \(Q_i\) 替换为 \((a_{ii} \cdot Q_i + b_i)\)),满足公式 (4) 中的关系。
因此,作者指出公式 (4) 是在仿射变换下 IGM 的必要条件。
2.2 如何映射?¶
对于新的价值函数 \(Q_{jt}'\),作者直接将其定义为:
(等等,这不就是 VDN 吗?别担心,让我们看看它与 VDN 的区别。)
由于 VDN 的分解过于充分,它与真实的 \(Q_{jt}\) 之间存在差距。因此,基于定理 1 中 \(V_{jt}(\boldsymbol{\tau})\) 的定义,作者提出使用 \(V_{jt}(\boldsymbol{\tau})\) 来修正 \(Q_{jt}\) 和 \(Q_{jt}'\) 之间的误差。这导致了:
通过这种方式,我们建立了 \(Q_{jt}\) 和 \(Q_{jt}'\) 之间的关系。注意 \([Q_i]\) 同时作为 \(Q_{jt}\) 和 \(Q_{jt}'\) 的分解,因此使用它们选择的最优动作是等价的。
如果我们直接将 \(Q_{jt}'\) 拟合为价值函数,那将与 VDN 算法相同——关键区别在于公式 (6) 中描述的关系。因此,学习 \(V_{jt}\) 变得特别重要。
3. 算法设计¶
3.1 结构框架¶
基于以上分析,至少需要学习三个组件:\(Q_i\)、\(Q_{jt}\) 和 \(V_{jt}\)。因此,QTRAN 算法框架相应地包括以下三个重要模块:
个体动作-价值网络:\(f_q : (\tau_i, u_i) \mapsto Q_i\);
联合动作-价值网络:\(f_r : (\boldsymbol{\tau} ,\mathbf{u}) \mapsto Q_{jt}\);
状态-价值网络:\(f_v : \boldsymbol{\tau} \mapsto V_{jt}\)。
算法框图:
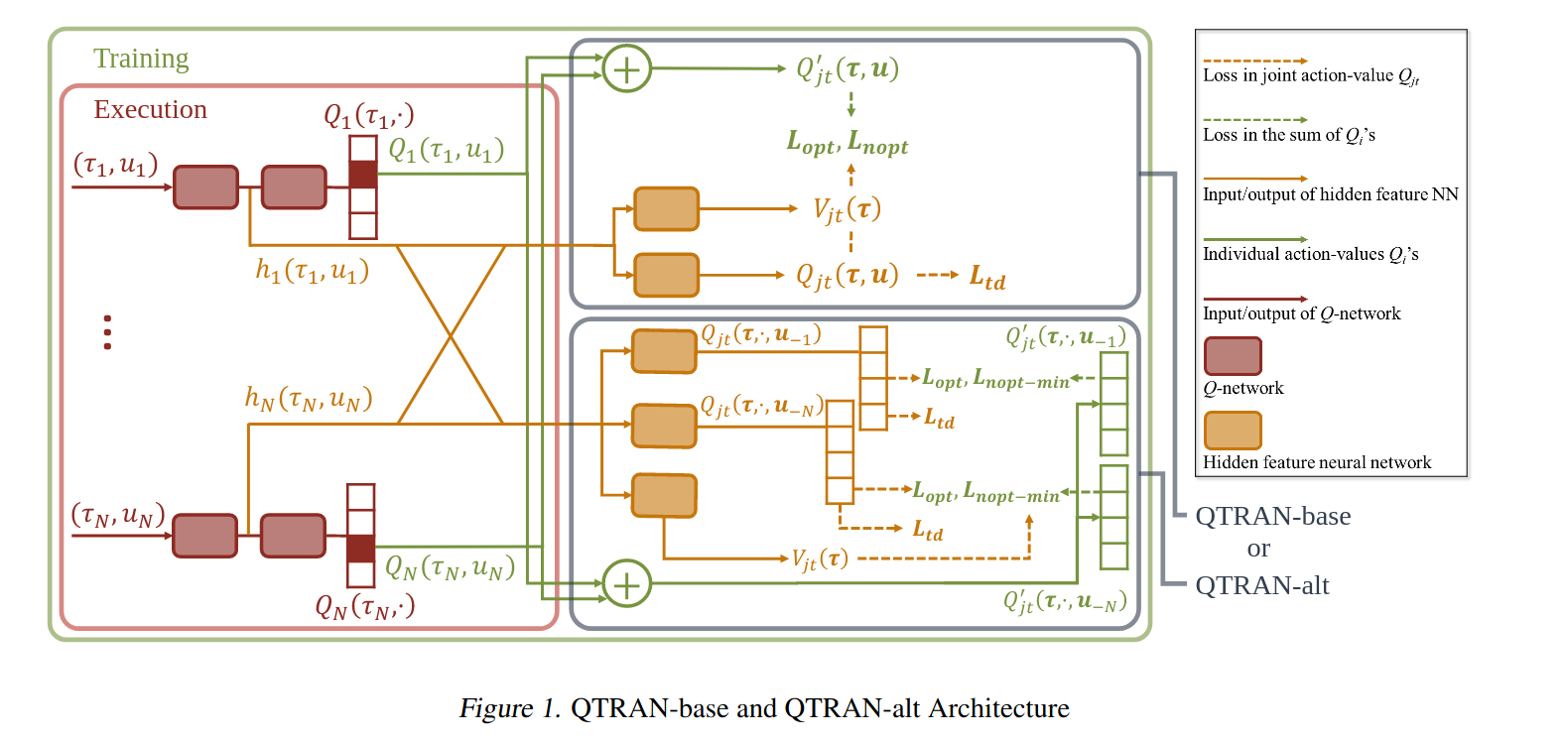
在图中,个体智能体网络 \(f_q\) 的设计类似于 VDN 和 QMIX。我们主要关注 \(f_r\) 和 \(f_v\) 的设计:
在更新该网络时,使用个体智能体网络来计算下一个动作的遍历,而不是在整个联合动作空间 \(\mathcal{U}^N\) 上执行 \(\arg\max\) 操作。
\(f_r\) 网络与 \(f_q\) 网络在较早的层中共享参数。
状态-价值网络 \(f_v\) 的功能类似于对偶网络中的 \(V(s)\)。此外,\(f_v\) 也在较早的层中与 \(f_q\) 网络共享参数。
3.2 损失函数¶
由于 QTRAN 有两个训练目标:\(Q_{jt}\) 和 \(V_{jt}\),损失函数设计如下:
\(L_{td}\) 用于拟合 \(Q_{jt}\);\(L_{opt}\) 和 \(L_{nopt}\) 用于拟合 \(V_{jt}\)。它们定义为:
这里,\(\theta^-\) 表示目标网络参数。\(L_{opt}\) 确保公式 (4a) 成立,而 \(L_{nopt}\) 确保公式 (4b) 成立。
3.3 QTRAN 的变体:QTRAN-alt¶
前面描述的 QTRAN 方法被作者称为 QTRAN-base。他们认为,适用于所有动作的公式 (4b) 中的条件是低效的,可能会对算法的稳定性和收敛速度产生负面影响。因此,他们修改了定理 1 中的条件 (4b),并提出了定理 2:
定理 2. 当 \(\mathbf{u} \neq \bar{\mathbf{u}}\) 时,用以下方程替换定理 1 中的条件 (4b) 仍然可以确保定理 1 的有效性:
其中 \(\mathbf{u}_{-i} = (u_1, \ldots, u_{i-1}, u_{i+1}, \ldots, u_N)\)。
定理 2 的证明同样可以在附录中找到。公式 (7) 比公式 (4b) 更严格,因为它迫使 \(Q'_{jt}\) 跟踪真实 \(Q_{jt}\) 的更新。基于定理 2 的算法称为 QTRAN-alt,其中 “alt” 代表 “alternative”。
为了便于计算公式 (7) 中的 min 函数,作者从 COMA 算法中的反事实基线概念中获得灵感,并提出了反事实联合网络。最终,
这允许将 \(L_{nopt}\) 损失重写为:
其中,
在 QTRAN-alt 中,\(L_{nopt\text{-}min}\) 的计算只需要遍历个体智能体的局部动作空间。然而,与 QTRAN-base 类似,\(L_{td}\) 和 \(L_{opt}\) 仍然需要遍历所有智能体的联合动作空间。
3.4 算法伪代码¶

3.5 案例研究:单状态矩阵博弈¶
为了展示两种 QTRAN 算法的性能,作者首先提出了一个简单的单步矩阵博弈案例。下表显示了相应的收益矩阵以及各种算法学习的 Q 值。这里,A、B 和 C 表示每个智能体可用的动作。(有关学习过程如何工作的详细信息,请参阅原文中的描述。)
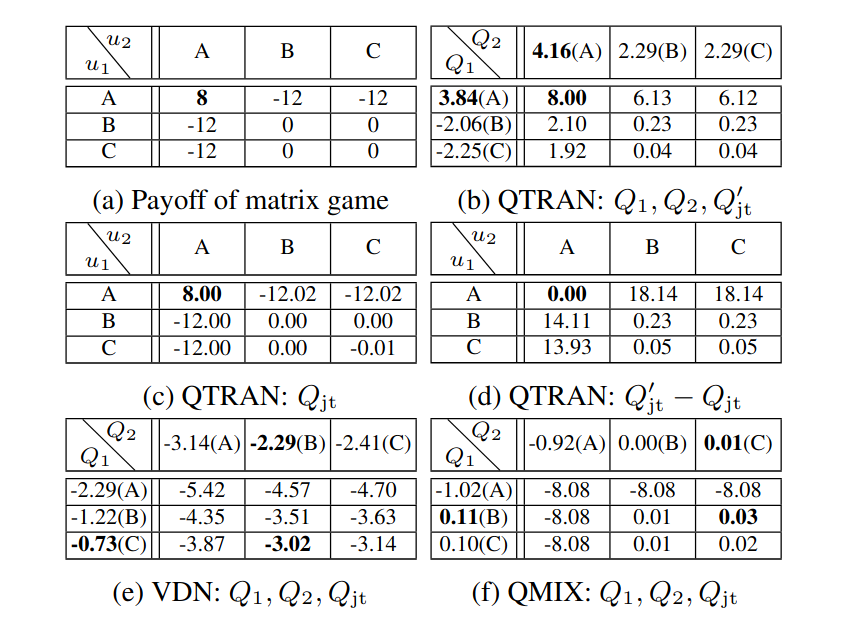
Table 1. 单步矩阵博弈模型,粗体表示最优 Q 值。¶
在这种情况下,收益矩阵是非单调的。因此,VDN 算法和 QMIX 算法都收敛到局部最优,而 QTRAN 可以几乎完美地近似真实的收益矩阵。从表 1 中,我们至少可以得出以下结论:
VDN 算法获得的价值函数与真实值偏差最大(表 e);
QMIX 无法准确近似动作组 AA 的 Q 值,只能达到局部最优(表 f);
通过有效补偿 VDN 与真实 Q 值之间的误差(表 d),QTRAN 学习了一个实现全局最优的分解价值函数(表 b 和 c),从而满足 IGM 条件。
由于这种情况下的动作数量有限,两种 QTRAN 变体之间的差异并不明显。为了解决这个问题,作者在具有 21 个动作的矩阵博弈上进行了 QTRAN-base 和 QTRAN-alt 之间的对比实验。结果如下:
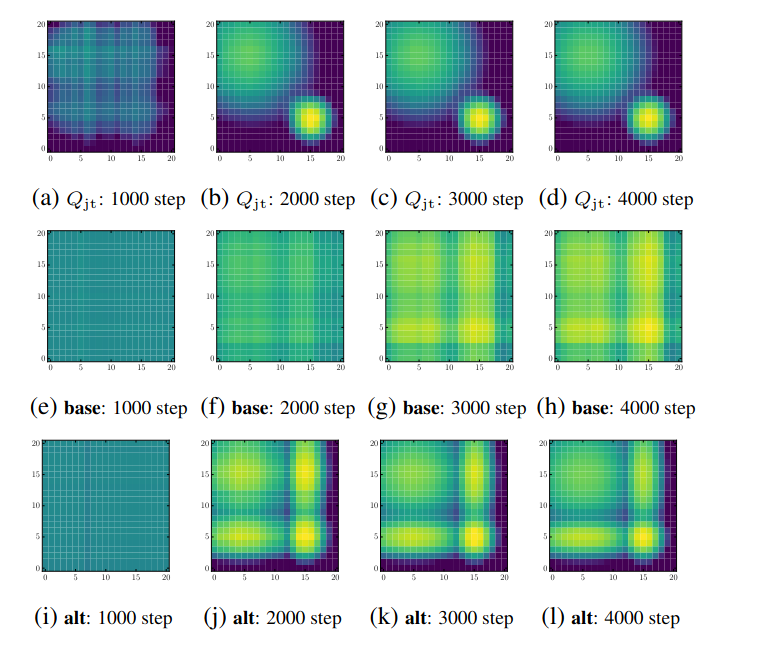
Figure 2. QTRAN-base 和 QTRAN-alt 算法的性能比较。¶
在图中,横坐标和纵坐标分别表示两个智能体选择的动作,颜色深度表示 Q 值的大小。从图中可以相对清楚地看出,对于 \(Q'_{jt}\) 的学习,QTRAN-base 很好地拟合了对应于最优动作的 Q 值,但对于非最优动作表现出较大的误差。相比之下,QTRAN-alt 对最优和非最优动作都实现了更准确的 Q 值近似。
在 XuanCe 中运行 QTRAN¶
在 XuanCe 中运行 QTRAN 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 QTRAN:
import xuance
runner = xuance.get_runner(method='qtran',
env='sc2', # 选择:mpe.
env_id='8m', # 选择:1c3sc5, 3m, MMM2, 25m.
is_test=False)
runner.run() # 或 runner.benchmark()
使用自定义配置运行¶
如果您想使用不同的配置运行 QTRAN,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 QTRAN:
import xuance
runner = xuance.get_runner(method='qtran',
env='sc2', # 选择:mpe.
env_id='8m', # 选择:1c3sc5, 3m, MMM2, 25m.
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run() # 或 runner.benchmark()
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 QTRAN,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
qtran_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 QTRAN:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_MULTI_AGENT_ENV
from xuance.environment import make_envs
from xuance.torch.agents.multi_agent_rl.qtran_agents import QTRAN_Agents
configs_dict = get_configs(file_dir="qtran_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_MULTI_AGENT_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = QTRAN_Agents(config=configs, envs=envs) # 从 XuanCe 创建 QTRAN 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@inproceedings{son2019qtran,
title={QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning},
author={Son, Kyunghwan and Kim, Daewoo and Kang, Wan Ju and Hostallero, David Earl and Yi, Yung},
booktitle={International Conference on Machine Learning},
pages={5887--5896},
year={2019},
organization={PMLR}
}