多智能体软执行器-评判器 (MASAC)¶
论文链接: https://arxiv.org/abs/2104.06655
多智能体软执行器-评判器(MA-SAC)是一种多智能体深度强化学习算法, 它整合了 SAC 算法的基本框架和价值函数分解。 它遵循中心化训练与去中心化执行(CTDE)范式,实现高效的异策略学习。 此外,它在离散和连续动作空间中部分缓解了信用分配问题。
下表列出了 MASAC 算法的一些一般特性:
MASAC 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
❌ |
评估策略与目标策略相同。 |
异策略 |
✅ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
✅ |
处理连续动作空间。 |
框架¶
下图显示了 MASAC 的算法结构。
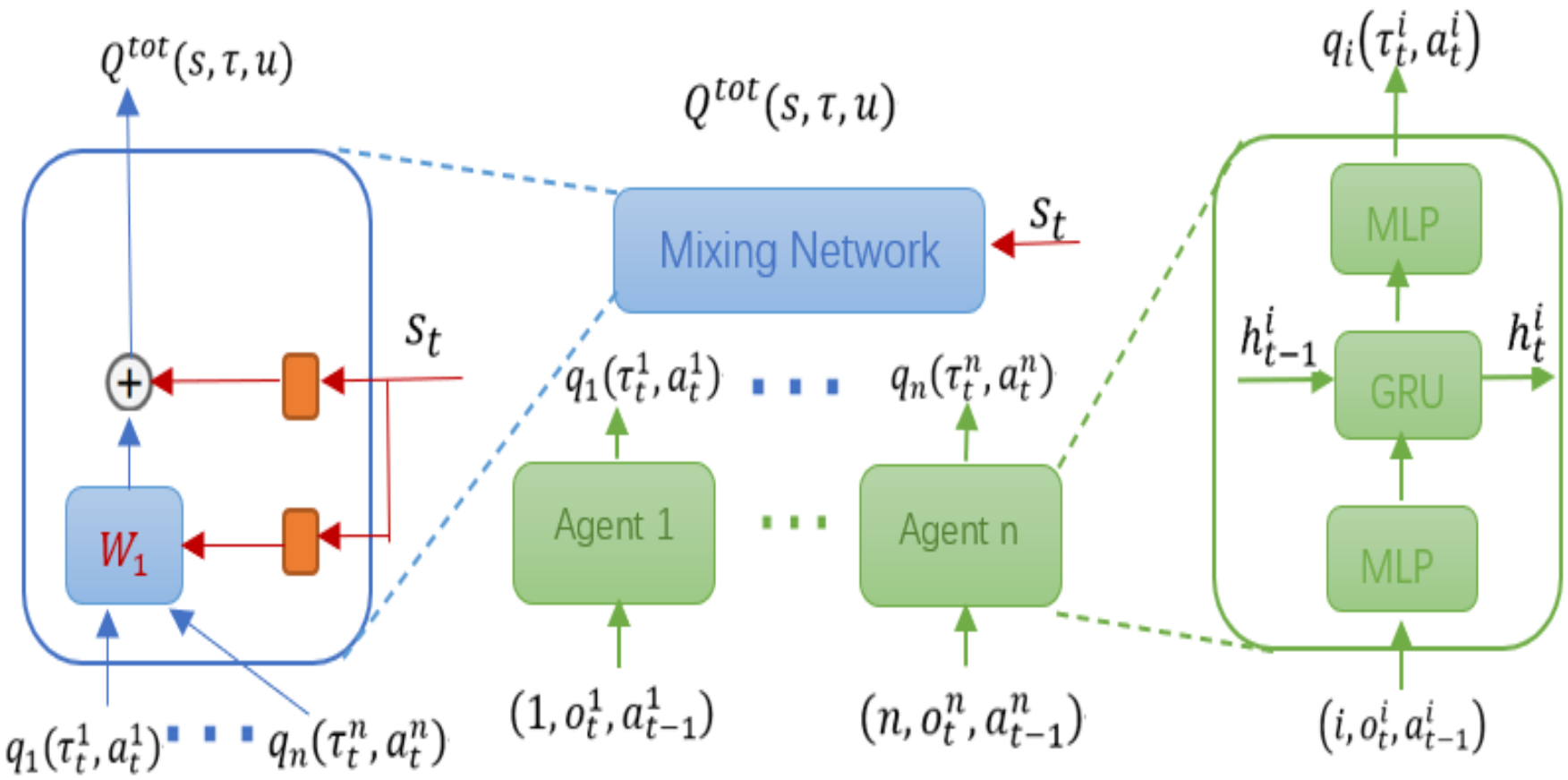
在此框架中,左:混合网络结构。红色图形是产生混合网络层权重和偏置的超网络。中:整体 Qmix 架构。右:智能体的局部 Q 网络,为绿色,\(i\) 表示相应的 one-hot 向量以区分不同的智能体。
MASAC 的核心思想¶
价值函数分解¶
每个智能体学习一个局部 Q 值函数,然后通过可学习的混合网络聚合以产生全局联合 Q 值。
\(q^{mix}\) 表示非线性单调分解结构。
多智能体软执行器-评判器¶
该方法采用软策略迭代的实用近似,MASAC 方法在多智能体设置中的评判器损失函数为:
其中 \(\phi\) 表示当前 Q 网络的参数,\(\phi_j^{\prime}\) 表示目标 Q 网络的参数。目标值定义为:
其中 \(\hat{Q}_{\phi_j^{\prime}}^{\mathrm{targ}}\) 可以写为:
其中 \(\alpha\log\pi\left(a_{t+1}\mid\tau_{t+1}\right)\) 被视为熵正则化项。
基于软策略的迭代过程,策略更新的目标如下:
\(\alpha\) 是一个超参数,控制最大化策略熵和期望折扣回报之间的权衡。它可以设计为类似于 SAC 的动态学习:
算法¶
MASAC 的完整训练算法如算法 1 所示:

在 XuanCe 中运行 MASAC¶
在 XuanCe 中运行 MASAC 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 MASAC:
import xuance
runner = xuance.get_runner(method='masac',
env='mpe',
env_id='simple_spread_v3',
is_test=False)
runner.run() # 或 runner.benchmark()
使用自定义配置运行¶
如果您想使用不同的配置运行 MASAC,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 MASAC:
import xuance
runner = xuance.get_runner(method='masac',
env='mpe',
env_id='simple_spread_v3',
config_path="my_config.yaml",
is_test=False)
runner.run() # 或 runner.benchmark()
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 MASAC,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
masac_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 MASAC:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import MASAC_Agents
configs_dict = get_configs(file_dir="masac_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = MASAC_Agents(config=configs, envs=envs) # 从 XuanCe 创建 MASAC 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@misc{pu2021decomposedsoftactorcriticmethod,
title={Decomposed Soft Actor-Critic Method for Cooperative Multi-Agent Reinforcement Learning},
author={Yuan Pu and Shaochen Wang and Rui Yang and Xin Yao and Bin Li},
year={2021},
eprint={2104.06655},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2104.06655},
}