价值分解执行器-评判器 (VDAC)¶
论文链接: https://ojs.aaai.org/index.php/AAAI/article/view/17353.
背景与动机¶
在多智能体强化学习(MARL)中,有效协调多个决策智能体以实现全局最优策略是核心挑战之一。典型方法可以分为两类范式:基于价值和基于策略。近年来,中心化训练与去中心化执行(CTDE)框架取得了显著进展。
其中,QMIX 作为典型的价值分解方法,通过单调混合网络将联合动作-价值函数 \(Q_{tot}\) 分解为每个智能体的局部动作-价值 \(Q_a\) 的非线性组合,在《星际争霸》微管理(SMAC)任务等基准测试中表现良好。然而,QMIX 依赖于异策略学习范式,难以高效集成到高效的同策略框架(如优势执行器-评判器,A2C)中,这限制了其样本效率和训练效率。
另一方面,尽管 COMA 等多智能体执行器-评判器方法具有良好的训练效率优势,但其性能仍显著低于 QMIX,存在明显的性能差距。这一矛盾促使研究人员探索一种既具有高训练效率又具有强策略性能的新架构。
为此,Su 等人(2021)提出了价值分解执行器-评判器(VDAC)框架,旨在弥合多智能体 Q 学习与执行器-评判器方法之间的差距,并构建一个既能在保证训练效率的同时又能提高算法性能的统一范式。
下表列出了 VDAC 算法的一些一般特性:
VDAC 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
✅ |
评估策略与目标策略相同。 |
异策略 |
❌ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
❌ |
处理连续动作空间。 |
核心思想¶
VDAC 的核心创新在于将”价值分解”概念从传统的动作-价值分解扩展到状态-价值分解,并将其嵌入到执行器-评判器架构中,形成新的信用分配机制。 其理论基础源于差异奖励机制:个体智能体的学习信号应与其对全局回报的边际贡献正相关。VDAC 将此概念形式化为以下单调性约束条件: $\( \frac{\partial V_{tot}(s)}{\partial V^{a}(\tau^{a})} \geq 0, \quad \forall a \in \{1, \ldots, n\} \)$ 其中:
\(V_{tot}(s)\):全局状态-价值函数,依赖于环境的真实状态 \(s\)。
\(V^{a}(\tau^{a})\):第 \(a\) 个智能体的局部状态-价值函数,依赖于其观测历史 \(\tau^{a}\)。
此条件确保当任何智能体的局部价值增加且其他智能体的策略保持不变时,整体系统价值不会降低,从而实现有效的信用分配和策略协调。
方法¶
VDAC-sum¶
VDAC-sum 是 VDAC 框架的基本实现。其核心思想是将全局状态-价值 \(V_{tot}(s)\) 表示为每个智能体的局部状态-价值 \(V^a(o^a)\) 的线性求和。该方法遵循以下分解形式:
其中 \(s\) 表示环境的真实状态,\(o^a\) 是智能体 \(a\) 的局部观测,\(V^a(o^a)\) 由分布式评判器估计。该评判器除了输出层外与相应智能体的执行器网络共享所有参数。这种参数共享机制不仅降低了模型复杂度,还促进了策略的泛化能力。 关键设计与理论基础
由于权重系数始终为 1(正数),上述线性组合自然满足 VDAC 所需的关键单调性条件:
此特性确保任何智能体对其局部状态-价值的改进都不会损害整体系统的长期回报期望,从而有效缓解信用分配问题。
使用最小二乘法优化局部评判器参数 \(\theta_v\)。损失函数定义为:
其中 \(y_t = \sum_{i=0}^{k - t - 1} \gamma^i r_i + \gamma^{k - t} V_{tot}(s_k)\) 是 n 步引导后的目标值。 基于简单的时序差分优势(TD advantage)计算策略梯度:
尽管 VDAC-sum 结构简洁并保证收敛,但其表示能力受到线性假设的限制,只能近似受限类别的中心化状态-价值函数。此外,此变体未充分利用全局状态信息进行训练,因此其性能上限低于具有额外状态输入的模型。
VDAC-mix¶
VDAC-mix 是 VDAC-sum 的扩展,旨在克服其有限的表示能力。该方法引入一个非负加权前馈神经网络(称为混合网络)以非线性方式融合每个智能体的局部状态值 \(V^a(o^a)\),从而生成全局状态值 \(V_{tot}(s)\):
其中,\(f_{mix}\) 是一个神经网络结构,其参数由超网络动态生成,其设计目标是近似任何单调递增函数。
分布式评判器仍然通过最小化预测误差进行训练:
VDAC-sum 中使用的 TD 优势策略梯度公式也被用于确保策略更新方向与全局价值改进一致。
VDAC-mix 显著增强了模型的表示能力,可以捕获更复杂的协作模式。实验表明,在高难度任务(如 3s5z、bane vs bane)中,VDAC-mix 的中位胜率显著优于其他基线方法,特别是在与 QMIX 的比较中表现出更高的稳定性和最终性能。
框架¶
下图显示了 VDAC-sum 的算法结构。
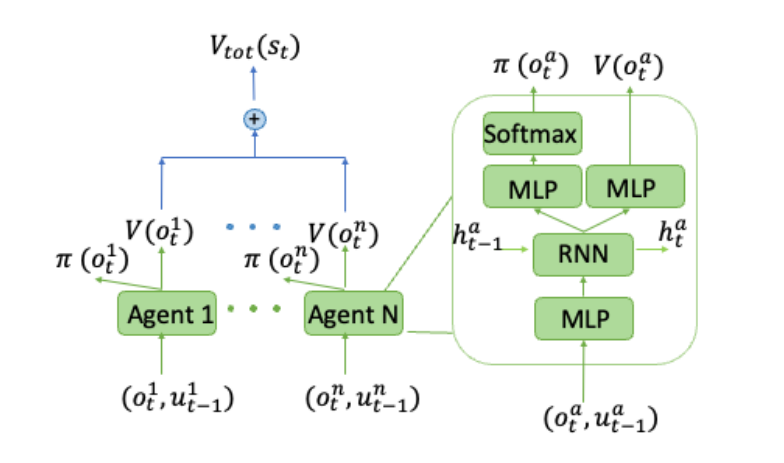
Figure 1. VDAC-sum¶
下图显示了 VDAC-mix 的算法结构。
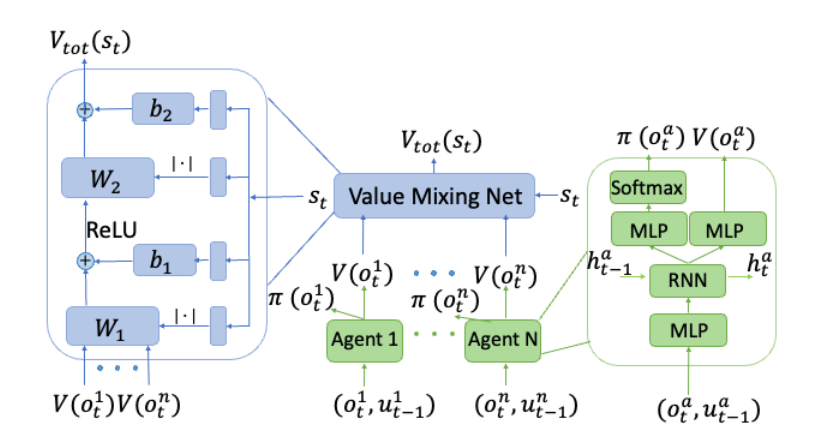
Figure 2. VDAC-mix¶
在 XuanCe 中运行 VDAC¶
在 XuanCe 中运行 VDAC 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 VDAC:
import xuance
runner = xuance.get_runner(method='vdac',
env='mpe',
env_id='simple_spread_v3',
is_test=False)
runner.run()
使用自定义配置运行¶
如果您想使用不同的配置运行 VDAC,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 VDAC:
import xuance
runner = xuance.get_runner(method='vdac',
env='mpe',
env_id='simple_spread_v3',
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run()
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 VDAC,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
vdac_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 VDAC:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import VDAC_Agents
configs_dict = get_configs(file_dir="vdac_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs)
Agent = VDAC_Agents(config=configs, envs=envs)
Agent.train(configs.running_steps // configs.parallels)
Agent.save_model("final_train_model.pth")
Agent.finish() # 完成训练。
引用¶
@inproceedings{su2021value,
title={Value-decomposition multi-agent actor-critics},
author={Su, Jianyu and Adams, Stephen and Beling, Peter},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
volume={35},
number={13},
pages={11352--11360},
year={2021}
}