多智能体深度确定性策略梯度 (MADDPG)¶
论文链接: https://arxiv.org/abs/1706.02275
多智能体深度确定性策略梯度(MA-DDPG)是一种多智能体深度强化学习算法, 它以 DDPG 算法为基线,采用中心化训练和去中心化执行作为训练方法。 该方法不仅适用于协作交互, 还适用于竞争性或混合交互,涉及物理和通信行为。
下表列出了 MADDPG 算法的一些一般特性:
MADDPG 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
❌ |
评估策略与目标策略相同。 |
异策略 |
✅ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
✅ |
处理连续动作空间。 |
框架¶
下图显示了 MADDPG 的算法结构。
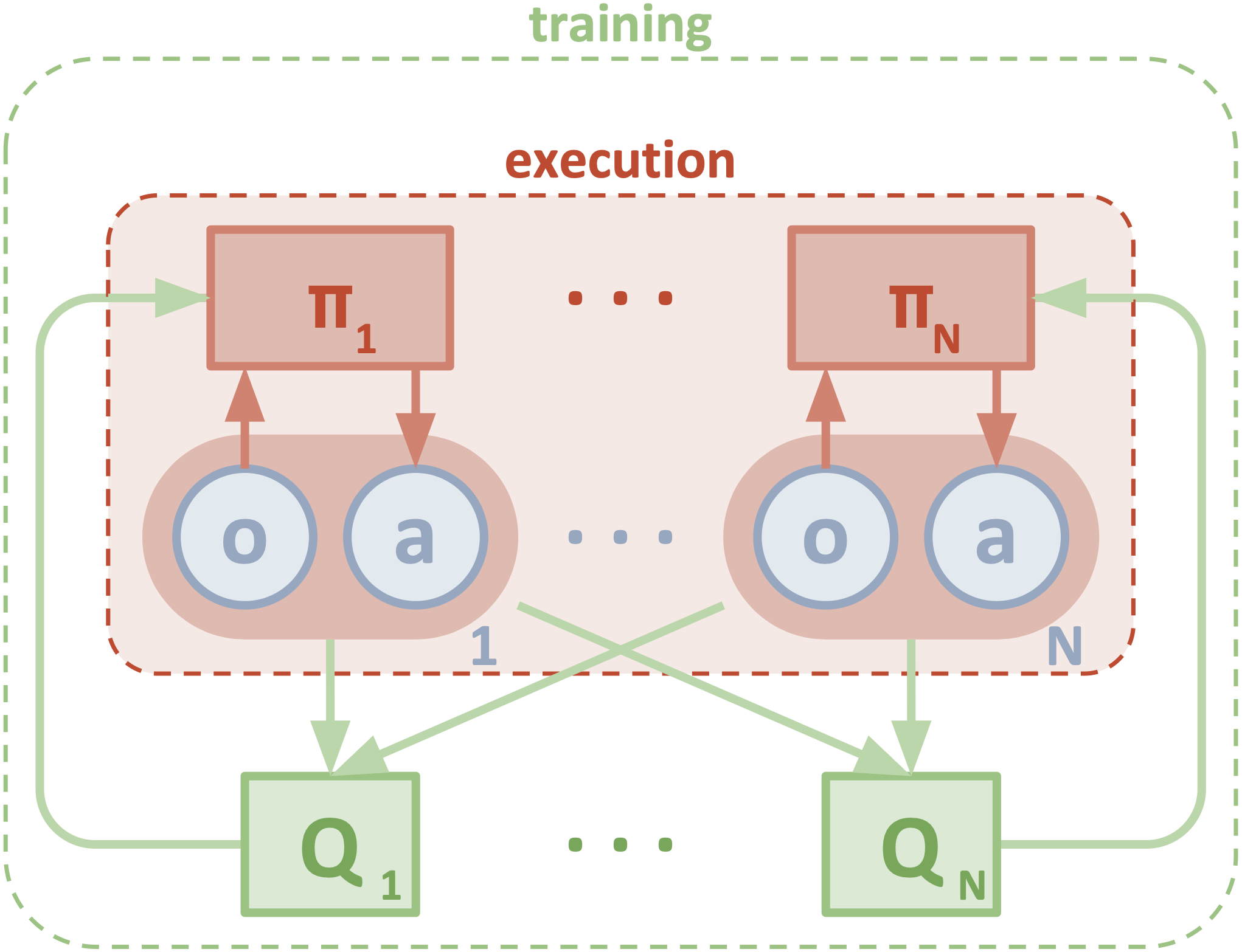
其中 \(\pi=(\pi_1,\ldots,\pi_N)\) 表示 N 个智能体的策略,它们分别由 N 个参数为 \(\theta=(\theta_1,\ldots,\theta_N)\) 的执行器网络拟合。
MADDPG 的核心思想¶
多智能体执行器-评判器¶
MADDPG 在以下约束下运行:
学习到的策略在执行时只能使用局部信息(它们自己的观测)。
它不假设环境动力学的可微模型。
它不假设智能体之间通信方法的任何特定结构(它不假设可微通信通道)。
基于上述约束,我们可以将智能体 \(i\) 的期望回报梯度 \(J \left( \theta_i \right)=\mathbb{E} \left( R_i \right)\) 写为:
其中 \(Q_i^\pi\left(x,a_1,\ldots,a_N\right)\) 是中心化动作-价值函数。除了状态信息 \(x\),它还以所有智能体的动作 \(a_1,\ldots,a_N\) 作为输入, 并最终输出智能体 \(i\) 的 Q 值。对于 \(x=(o_1,\ldots,o_N,\mathrm{X})\),它可以包括所有智能体的观测,以及可能存在的其他有用的附加信息。 对于确定性策略梯度,我们可以考虑 N 个连续策略 \(\mu_{\theta_i}\),那么梯度可以写为:
其中经验回放缓冲区 \(D\) 包含数据 \((x,x^{\prime},a_1,\ldots,a_N,r_1,\ldots,r_N)\),包括所有智能体的经验。 对于中心化动作-价值函数 \(Q_i^\mu\),它可以使用以下损失函数进行更新:
其中 \(y=r_i+\gamma{Q_i}^{\mu^\prime}(x^\prime,a_1^\prime,\ldots,a_N^\prime)\left|\right._{a^\prime_j=\mu^\prime_j(o_j)}\), 在 y 方程中,\(\mu^\prime=(\mu_{\theta_1}^\prime,\ldots,\mu_{\theta_N}^\prime)\) 是用于更新价值函数的目标策略集。
具有策略集成的智能体¶
多智能体强化学习的一个重要问题是环境是非平稳的,因为其他智能体的策略不断变化,特别是在竞争性设置中。 为了解决这个问题,作者提出了策略集成训练的概念,它训练 \(K\) 个不同的子策略,然后在每个回合中为每个智能体随机选择一个特定的子策略执行。 对于智能体 \(i\),其目标函数可以更改为:
其中 \(unif\left(1,K\right)\) 表示子策略索引集,\(K\) 表示子策略索引。 那么相应的策略梯度可以重写为:
算法¶
MADDPG 的完整训练算法如算法 1 所示:

在 XuanCe 中运行 MADDPG¶
在 XuanCe 中运行 MADDPG 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 MADDPG:
import xuance
runner = xuance.get_runner(method='maddpg',
env='mpe', # 选择:mpe, Drones, NewEnv_MAS.
env_id='simple_spread_v3', # 选择:simple_spread_v3 等。
is_test=False)
runner.run() # 或 runner.benchmark()
对于智能体可以分为两个或多个阵营的竞争性任务,您可以通过以下方式运行演示:
import xuance
runner = xuance.get_runner(method=["maddpg", "iddpg"],
env='mpe', # 选择:mpe.
env_id='simple_push_v3', # 选择:simple_adversary_v3, simple_push_v3 等。
is_test=False)
runner.run()
在这个演示中,mpe/simple_push_v3 环境中的智能体分为两个阵营,分别命名为 “adversary_0” 和 “agent_0”。 “adversary” 是 MADDPG 智能体,”agent” 是 IDDPG 智能体。
使用自定义配置运行¶
如果您想使用不同的配置运行 MADDPG,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 MADDPG:
import xuance
runner = xuance.get_runner(method='maddpg',
env='mpe', # 选择:mpe, Drones, NewEnv_MAS.
env_id='simple_spread_v3', # 选择:simple_spread_v3 等。
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run() # 或 runner.benchmark()
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 MADDPG,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
maddpg_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 MADDPG:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import MADDPG_Agents
configs_dict = get_configs(file_dir="maddpg_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = MADDPG_Agents(config=configs, envs=envs) # 从 XuanCe 创建 MADDPG 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@article{lowe2017multi,
title={Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments},
author={Lowe, Ryan and Wu, Yi and Tamar, Aviv and Harb, Jean and Abbeel, Pieter and Mordatch, Igor},
journal={Neural Information Processing Systems (NIPS)},
year={2017}
}