通信神经网络 (CommNet)¶
在多智能体强化学习(MARL)的协作任务中, 例如机器人团队运输和交通路口车辆调度, 智能体通常只有局部观测(例如,汽车只能看到 3×3 周围区域内的其他车辆)。 为了实现团队目标,通过通信进行信息共享是必不可少的。
CommNet 算法由纽约大学的 Sukhbaatar 等人在 NIPS 2016 上提出, 是一个使智能体能够自主学习连续通信协议的 MARL 模型。
下表列出了 CommNet 算法的一些一般特性:
CommNet 的特性 |
值 |
描述 |
|---|---|---|
完全去中心化 |
❌ |
智能体之间没有通信。 |
完全中心化 |
❌ |
智能体将所有信息发送给中央控制器,控制器将为所有智能体做出决策。 |
中心化训练与去中心化执行(CTDE) |
✅ |
在训练中使用中央控制器,在执行中放弃。 |
同策略 |
✅ |
评估策略与目标策略相同。 |
异策略 |
❌ |
评估策略与目标策略不同。 |
无模型 |
✅ |
不需要准备环境动力学模型。 |
基于模型 |
❌ |
需要环境模型来训练策略。 |
离散动作 |
✅ |
处理离散动作空间。 |
连续动作 |
✅ |
处理连续动作空间。 |
问题背景与研究动机¶
早期的 MARL 方法有明显的缺陷:
要么完全不允许智能体之间通信(例如,独立 Q 学习), 使它们变成无法协作的”信息孤岛”——例如,多个机器人竞争搬运同一个箱子,导致效率低下; 要么通信协议是手动预定义的,例如让机器人每次都报告其位置。 这种固定协议缺乏灵活性,在切换到其他任务时可能会失败(例如,机器人灭火)。 更成问题的是,在许多现实场景中, 智能体的数量是动态变化的(例如,车辆不断进入和离开高速公路)。 然而,传统的全连接模型具有固定的输入和输出维度, 使它们完全无法处理这种”智能体数量的波动”。
CommNet 的核心机制:通信模型与特性¶
要理解 CommNet,首先需要掌握其通信逻辑 ——智能体如何生成通信信号、交换信号以及使用信号来调整其动作。 本节分为两个部分:”基本模型结构”和”核心特性”。
基本通信模型:从状态到动作的三步过程¶
CommNet 的整体框架可以概括为三步过程:”编码 → 通信 → 解码”, 核心是连续通信向量(区别于离散符号)和动态更新的通信规则。 我们首先定义关键符号:
假设有 \(J\) 个智能体。每个智能体 \(j\) 的局部观测为 \(s_j\), 所有智能体的观测集合为 \(s=\{s_{1},s_{2},...,s_{J}\}\)。
\(h_j^i\):智能体 \(j\) 在第 \(i\) 次通信步骤后的隐藏状态(存储其自身观测和接收到的通信信息)。
\(c_j^i\):智能体 \(j\) 在第 \(i\) 步接收到的通信向量(来自其他智能体的信号之和)。
\(K\):通信步骤数(可以理解为智能体在做出决策前进行”多少轮通信”)。
整个模型过程如下:
编码(观测到隐藏状态)¶
首先,使用编码器 \(r(\cdot)\) 将每个智能体的局部观测 \(s_j\) 转换为初始隐藏状态 \(h_j^0\), 公式为:\(h_j^0=r(s_j)\)。
编码器的形式取决于任务。 本质上,它将”原始观测”转换为可以由神经网络处理的特征。
初始通信向量 \(c_j^0 = 0\)(最初没有接收到信号)。
多轮通信(隐藏状态和通信向量的更新)¶
这是 CommNet 的核心——在每一轮中,智能体基于自己的隐藏状态和接收到的通信信号更新新的隐藏状态, 然后将新状态”广播”给其他智能体,作为下一轮的通信信号。 有两个关键公式:
隐藏状态更新¶
每个智能体 \(j\) 使用模块 \(f^i\)(通常是 MLP)处理 \(h_j^i\) 和 \(c_j^i\) 以获得 \(h_j^{i+1}\):
在公式\((1)\)中,如果 \(f^i\) 是单层线性层 + 非线性激活 \(\sigma\)(例如,ReLU),可以展开为:\(h_j^{i+1}=\sigma(H^ih_j^i+C^ic_j^i)\)。
其中 \(H^i\) 是”隐藏状态权重”,\(C^i\) 是”通信信号权重”。
模型可以看作是前馈网络,层为 \(\mathbf{h}^{i+1}=\sigma\!\left(T^i\mathbf{h}^i\right)\) 其中 \(\mathbf{h}^i\) 是所有 \(h_j^i\) 的拼接,\(T^i\) 采用分块形式,其中 \(\bar{C}^i = \frac{C^i}{J-1}\):
一个关键点是 \(T\) 是动态大小的,因为智能体的数量可能变化。这促使在公式\(`(2)`\)中使用归一化因子 \(J − 1\),
它通过通信智能体的数量重新缩放通信向量。 还要注意 \(T^i\) 是置换不变的,因为所有智能体模块共享参数(\(C^i\),\(H^i\)),因此智能体的顺序无关紧要。
通信向量更新¶
每个智能体 \(j\) 接收到的下一轮通信信号 \(c_j^{i+1}\) 是所有其他智能体 \(j^{\prime}\neq j\) 的新隐藏状态 \(h_{j^{\prime}}^{i+1}\) 的平均值 (除以 \(J - 1\) 进行归一化,以避免智能体数量影响信号幅度):
解码(隐藏状态到动作)¶
经过 \(K\) 轮通信后,解码器 \(q(\cdot)\)(通常是线性层 + Softmax)将最终隐藏状态 \(h_j^K\) 转换为动作分布, 然后采样以获得智能体 \(j\) 的动作 \(a_j\):
完整的 CommNet 模型¶
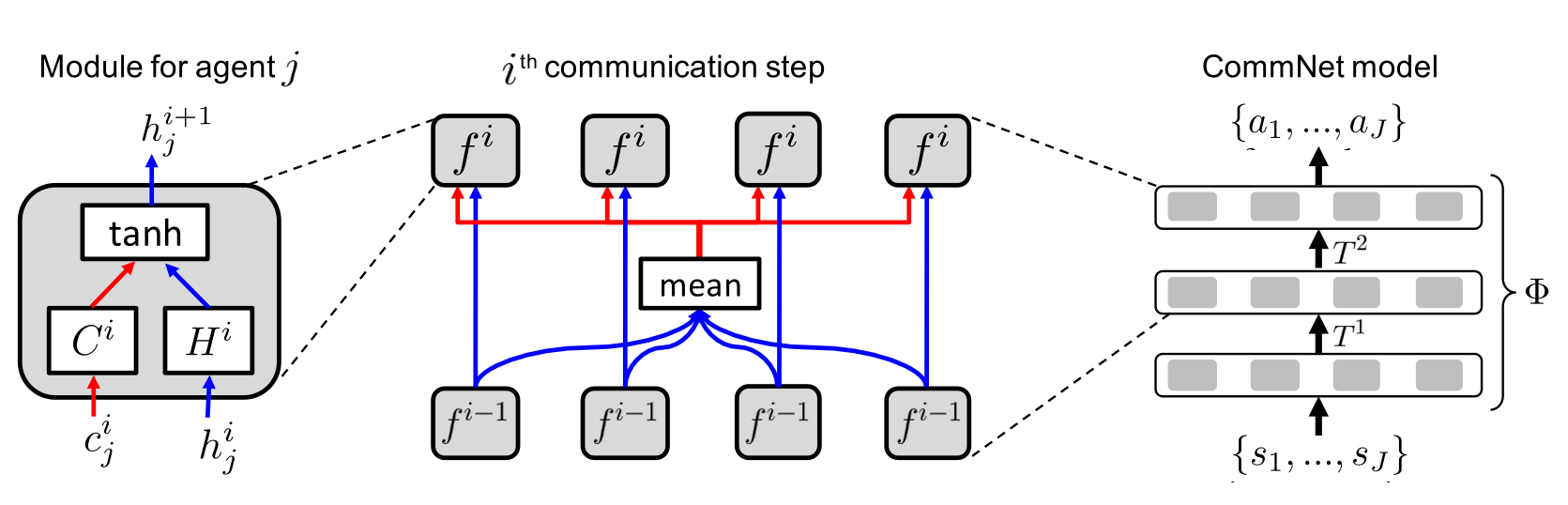
Figure 1: CommNet 模型概览¶
CommNet 交替进行计算和通信,以便智能体可以共享信息。 左:智能体 \(j\) 的每个智能体模块:块 \(f^i\) 接收 \(H^i_j\)(蓝色)和 \(C^i_j\)(红色),将它们拼接, 应用非线性(例如,tanh),并输出 \(h^{i+1}_j\)。 中:一次通信跳跃(第 \(i\) 次):每个智能体隐藏状态的一部分(蓝色)向前传递; 另一部分发送到共享通道(红色)。通道应用均值聚合并将结果广播回每个智能体,用于下一跳。 右:完整的 CommNet:给定输入 \({s_1,\dots,s_J}\),网络运行两次通信跳跃(这里是 \(T^1,T^2\))并输出动作 \({a_1,\dots,a_J}\)。
模型扩展:针对更多场景的改进¶
为了满足不同任务的需求,CommNet 有三个重要的扩展:
扩展 1:局部连通性(替代全局广播)
并非所有智能体都需要”完全通信” ——例如,在交通任务中,远处的汽车不需要向附近的汽车发送信号。 此时,\(N(j)\) 用于表示智能体 \(j\) 的”通信邻居”(例如,3×3 范围内的其他汽车), 通信向量更新为邻居状态的平均值:
扩展 2:跳跃连接(保留初始观测)
在某些任务中,初始观测(例如,智能体 ID)很重要。 因此,\(h_j^0\) 也用作 \(f^i\) 的输入,以避免在通信过程中丢失关键信息:
扩展 3:时间递归(处理动态过程)
对于多步骤任务(例如,多轮战斗任务), 模型被修改为 RNN/LSTM,允许隐藏状态跨时间步传递以记住先前的通信历史:
其中 \(t\) 是时间步,在每个时间步对动作进行采样。
CommNet 的核心特性¶
这些设计使 CommNet 具有传统模型所没有的优势:
特性 1:置换不变性
智能体的顺序不影响结果。 由于通信向量是”其他智能体状态的平均值”,T 矩阵(隐藏状态更新的整体权重矩阵)是块对称的。 无论智能体的顺序如何变化,最终的动作分布都保持不变——这对于动态添加的智能体至关重要。
特性 2:动态智能体适应
由于通信向量的归一化因子为 \(J-1\)(或 \(|N(j)|\)), T 矩阵的大小会随着智能体数量 \(J\) 动态调整。 它可以在不重新训练的情况下处理”智能体加入/离开”的场景(例如,交通路口的车辆增多或减少)。
特性 3:可微分的连续通信
通信向量是连续值, 因此整个模型可以通过反向传播进行训练 ——支持监督学习(例如,拉杆任务中”按 ID 顺序拉杆”的标签) 和强化学习(例如,交通任务中”减少碰撞”的奖励)。 它比离散通信更灵活(离散通信需要额外的 RL 训练)。
算法设计:训练方法与基线比较¶
CommNet 的训练根据任务是否具有”监督信号”分为两种方法, 并与三个经典基线进行比较以突出其优势。
两种训练方法¶
监督学习¶
如果每个动作都有正确的标签(例如,在拉杆任务中,”智能体按 ID 顺序拉不同的杠杆”是正确的解决方案), 直接使用交叉熵损失进行训练:
其中 \(a_j^*\) 是正确的动作。
强化学习训练¶
如果没有监督信号(例如,在交通任务中,不知道”何时正确刹车”), 使用策略梯度 + 基线进行训练。
用 \(s(1), ..., s(T)\) 表示回合中的状态,用 \(a(1), ..., a(T)\) 表示在每个状态下采取的动作, 其中 T 是回合长度。基线是状态的标量函数 b(s, θ), 通过模型上产生动作概率的额外头部计算。 除了用策略梯度最大化期望奖励外, 模型还经过训练以最小化基线值与实际奖励之间的距离。 因此,在完成一个回合后,我们通过以下方式更新模型参数 \(\theta\):
其中 \(a(t)\) 是 \(a_1(t), a_2(t), ..., a_J(t)\) 的拼接,\(s(t)\) 是 \(s_1(t), s_2(t), ..., s_J(t)\) 的拼接 \(b(s(t), \theta)\) 是状态价值基线(减少方差),\(\alpha\) 是平衡项(论文中设为 0.03)。
读者可以查看补充材料了解详细信息。
基线模型:CommNet 的优势是什么?¶
论文比较了三个主流基线,结果证明了 CommNet 的优势:
基线模型 |
核心逻辑 |
缺点 |
|---|---|---|
独立控制器 |
每个智能体使用单独的 Q 网络,不进行通信 |
无法协作(例如,智能体在拉杆任务中竞争杠杆) |
全连接模型 |
拼接所有智能体的观测,并使用全连接 MLP 输出动作 |
固定的智能体数量(更改 \(J\) 时需要重新训练)且对顺序敏感 |
离散通信 |
智能体发送离散符号(例如,0/1),符号的含义通过 RL 训练 |
通信信号不可微,训练不稳定,性能不如连续通信 |
CommNet 的详细参数优化过程¶
特性:全局统一网络 + 共享参数
1. 参数初始化¶
观测预处理:将 \(J\) 个智能体的局部观测 \(s_j\) 拼接成全局观测向量 \(\pmb{s} = [s_1, s_2, ..., s_J]\)。 使用编码器 \(r(\cdot)\) 将此向量转换为初始隐藏状态 \(h_j^0 = r(s_j)\),编码器参数在所有智能体之间共享。
网络参数初始化:初始化共享参数,包括:
隐藏状态更新权重 \(H^i\) 和 \(C^i\)(有 \(K\) 轮通信,每轮有一组 \(H^i, C^i\));
解码器参数 \(q(\cdot)\);
2. 训练循环阶段¶
前向传播:全局观测 → 通信 → 动作输出 (详细信息已在基本通信模型部分展示)。
全局目标函数的构建: 根据任务类型选择监督学习或**强化学习(RL)**目标 这些公式已在两种训练方法的内容中展示。
反向传播和参数更新
步骤 1:梯度计算:沿路径”解码器 → 通信层 → 编码器”执行反向传播
步骤 2:共享参数更新:更新所有共享参数。
在 XuanCe 中运行 CommNet¶
在 XuanCe 中运行 CommNet 之前,您需要准备 conda 环境并按照
安装步骤 安装 xuance。
运行内置演示¶
完成安装后,您可以打开 Python 控制台并使用以下命令直接运行 CommNet:
import xuance
runner = xuance.get_runner(method='commnet',
env='mpe', # 选择:mpe, sc2
env_id='simple_spread_v3', # 选择:simple_spread_v3 等
is_test=False)
runner.run()
使用自定义配置运行¶
如果您想使用不同的配置运行 CommNet,可以创建一个新的 .yaml 文件,例如 my_config.yaml。
然后,通过以下代码块运行 CommNet:
import xuance as xp
runner = xp.get_runner(method='commnet',
env='mpe', # 选择:mpe, sc2
env_id='simple_spread_v3', # 选择:simple_spread_v3 等
config_path="my_config.yaml", # my_config.yaml 文件的路径应该是正确的。
is_test=False)
runner.run() # 或 runner.benchmark()
要了解更多关于配置的信息,请访问 配置教程。
使用自定义环境运行¶
如果您想在 XuanCe 中未包含的自己的环境中运行 XuanCe 的 CommNet,
您需要按照
新环境教程 中的步骤定义新环境。
然后,准备配置文件
commnet_myenv.yaml。
之后,您可以使用以下代码在自己的环境中运行 CommNet:
import argparse
from xuance.common import get_configs
from xuance.environment import REGISTRY_ENV
from xuance.environment import make_envs
from xuance.torch.agents import CommNet_Agents
configs_dict = get_configs(file_dir="commnet_myenv.yaml")
configs = argparse.Namespace(**configs_dict)
REGISTRY_ENV[configs.env_name] = MyNewEnv
envs = make_envs(configs) # 创建并行环境。
Agent = CommNet_Agents(config=configs, envs=envs) # 从 XuanCe 创建 CommNet 智能体。
Agent.train(configs.running_steps // configs.parallels) # 训练模型多个步骤。
Agent.save_model("final_train_model.pth") # 将模型保存到 model_dir。
Agent.finish() # 完成训练。
引用¶
@article{sukhbaatar2016learning,
title={Learning multiagent communication with backpropagation},
author={Sukhbaatar, Sainbayar and Fergus, Rob and others},
journal={Advances in neural information processing systems},
volume={29},
year={2016}
}